🧹 chore: clean up Jan Server
This commit is contained in:
parent
7b5060c9be
commit
3b30467c9c
@ -21,11 +21,6 @@
|
||||
"title": "Integrations",
|
||||
"display": "hidden"
|
||||
},
|
||||
"api-reference": {
|
||||
"type": "page",
|
||||
"title": "API reference",
|
||||
"display": "hidden"
|
||||
},
|
||||
"handbook": {
|
||||
"type": "page",
|
||||
"title": "Handbook",
|
||||
|
||||
@ -1,20 +0,0 @@
|
||||
{
|
||||
"get-started-separator": {
|
||||
"title": "Get started",
|
||||
"type": "separator"
|
||||
},
|
||||
"index": "Overview",
|
||||
"installation": "Installation",
|
||||
"configuration": "Configuration",
|
||||
"core-concepts-separator": {
|
||||
"title": "Core concepts",
|
||||
"type": "separator"
|
||||
},
|
||||
"api-reference": "API Reference",
|
||||
"resource-separator": {
|
||||
"title": "Resources",
|
||||
"type": "separator"
|
||||
},
|
||||
"architecture": "Architecture",
|
||||
"development": "Development"
|
||||
}
|
||||
@ -1,378 +0,0 @@
|
||||
---
|
||||
title: API Reference
|
||||
description: Complete API documentation for Jan Server endpoints and OpenAI compatibility.
|
||||
---
|
||||
|
||||
## Base URL
|
||||
|
||||
All API endpoints are available at the API gateway base URL:
|
||||
|
||||
```
|
||||
http://localhost:8080/api/v1
|
||||
```
|
||||
|
||||
The API gateway automatically forwards port 8080 when using the standard deployment scripts.
|
||||
|
||||
## Authentication
|
||||
|
||||
Jan Server supports multiple authentication methods:
|
||||
|
||||
### JWT Token Authentication
|
||||
|
||||
Include JWT token in the Authorization header:
|
||||
|
||||
```bash
|
||||
curl -H "Authorization: Bearer <jwt_token>" \
|
||||
http://localhost:8080/api/v1/protected-endpoint
|
||||
```
|
||||
|
||||
### API Key Authentication
|
||||
|
||||
Include API key in the Authorization header:
|
||||
|
||||
```bash
|
||||
curl -H "Authorization: Bearer <api_key>" \
|
||||
http://localhost:8080/api/v1/protected-endpoint
|
||||
```
|
||||
|
||||
## OpenAI-Compatible Endpoints
|
||||
|
||||
Jan Server implements OpenAI-compatible endpoints for seamless integration with existing tools.
|
||||
|
||||
### Chat Completions
|
||||
|
||||
**Endpoint**: `POST /api/v1/chat/completions`
|
||||
|
||||
Standard OpenAI chat completions API for conversational AI.
|
||||
|
||||
```bash
|
||||
curl -X POST http://localhost:8080/api/v1/chat/completions \
|
||||
-H "Content-Type: application/json" \
|
||||
-H "Authorization: Bearer <token>" \
|
||||
-d '{
|
||||
"model": "jan-v1-4b",
|
||||
"messages": [
|
||||
{"role": "user", "content": "Hello, how are you?"}
|
||||
],
|
||||
"max_tokens": 100,
|
||||
"temperature": 0.7
|
||||
}'
|
||||
```
|
||||
|
||||
**Parameters:**
|
||||
- `model` (string): Model identifier (`jan-v1-4b`)
|
||||
- `messages` (array): Conversation history
|
||||
- `max_tokens` (integer): Maximum response tokens
|
||||
- `temperature` (float): Response randomness (0.0 to 2.0)
|
||||
- `stream` (boolean): Enable streaming responses
|
||||
|
||||
### Model Information
|
||||
|
||||
**Endpoint**: `GET /api/v1/models`
|
||||
|
||||
List available models:
|
||||
|
||||
```bash
|
||||
curl http://localhost:8080/api/v1/models
|
||||
```
|
||||
|
||||
**Response:**
|
||||
```json
|
||||
{
|
||||
"object": "list",
|
||||
"data": [
|
||||
{
|
||||
"id": "jan-v1-4b",
|
||||
"object": "model",
|
||||
"created": 1234567890,
|
||||
"owned_by": "jan"
|
||||
}
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
### Completions (Text Generation)
|
||||
|
||||
**Endpoint**: `POST /api/v1/completions`
|
||||
|
||||
Text completion endpoint:
|
||||
|
||||
```bash
|
||||
curl -X POST http://localhost:8080/api/v1/completions \
|
||||
-H "Content-Type: application/json" \
|
||||
-H "Authorization: Bearer <token>" \
|
||||
-d '{
|
||||
"model": "jan-v1-4b",
|
||||
"prompt": "The meaning of life is",
|
||||
"max_tokens": 50
|
||||
}'
|
||||
```
|
||||
|
||||
## Authentication Endpoints
|
||||
|
||||
### OAuth2 Google Login
|
||||
|
||||
**Endpoint**: `GET /auth/google`
|
||||
|
||||
Redirects to Google OAuth2 authorization:
|
||||
|
||||
```bash
|
||||
curl http://localhost:8080/auth/google
|
||||
```
|
||||
|
||||
### OAuth2 Callback
|
||||
|
||||
**Endpoint**: `GET /auth/google/callback`
|
||||
|
||||
Handles OAuth2 callback and issues JWT token:
|
||||
|
||||
```
|
||||
http://localhost:8080/auth/google/callback?code=<auth_code>&state=<state>
|
||||
```
|
||||
|
||||
### Token Refresh
|
||||
|
||||
**Endpoint**: `POST /api/v1/auth/refresh`
|
||||
|
||||
Refresh expired JWT tokens:
|
||||
|
||||
```bash
|
||||
curl -X POST http://localhost:8080/api/v1/auth/refresh \
|
||||
-H "Authorization: Bearer <expired_token>"
|
||||
```
|
||||
|
||||
## User Management
|
||||
|
||||
### User Profile
|
||||
|
||||
**Endpoint**: `GET /api/v1/user/profile`
|
||||
|
||||
Get current user profile:
|
||||
|
||||
```bash
|
||||
curl -H "Authorization: Bearer <token>" \
|
||||
http://localhost:8080/api/v1/user/profile
|
||||
```
|
||||
|
||||
### API Keys
|
||||
|
||||
**Endpoint**: `POST /api/v1/user/api-keys`
|
||||
|
||||
Generate new API key:
|
||||
|
||||
```bash
|
||||
curl -X POST http://localhost:8080/api/v1/user/api-keys \
|
||||
-H "Authorization: Bearer <token>" \
|
||||
-H "Content-Type: application/json" \
|
||||
-d '{
|
||||
"name": "Development Key",
|
||||
"permissions": ["read", "write"]
|
||||
}'
|
||||
```
|
||||
|
||||
## Conversation Management
|
||||
|
||||
### Create Conversation
|
||||
|
||||
**Endpoint**: `POST /api/v1/conversations`
|
||||
|
||||
Create new conversation:
|
||||
|
||||
```bash
|
||||
curl -X POST http://localhost:8080/api/v1/conversations \
|
||||
-H "Authorization: Bearer <token>" \
|
||||
-H "Content-Type: application/json" \
|
||||
-d '{
|
||||
"title": "My Conversation",
|
||||
"model": "jan-v1-4b"
|
||||
}'
|
||||
```
|
||||
|
||||
### List Conversations
|
||||
|
||||
**Endpoint**: `GET /api/v1/conversations`
|
||||
|
||||
Get user's conversations:
|
||||
|
||||
```bash
|
||||
curl -H "Authorization: Bearer <token>" \
|
||||
http://localhost:8080/api/v1/conversations
|
||||
```
|
||||
|
||||
### Get Conversation
|
||||
|
||||
**Endpoint**: `GET /api/v1/conversations/{id}`
|
||||
|
||||
Get specific conversation with message history:
|
||||
|
||||
```bash
|
||||
curl -H "Authorization: Bearer <token>" \
|
||||
http://localhost:8080/api/v1/conversations/123
|
||||
```
|
||||
|
||||
## Health and Status
|
||||
|
||||
### Health Check
|
||||
|
||||
**Endpoint**: `GET /health`
|
||||
|
||||
Basic health check:
|
||||
|
||||
```bash
|
||||
curl http://localhost:8080/health
|
||||
```
|
||||
|
||||
**Response:**
|
||||
```json
|
||||
{
|
||||
"status": "ok",
|
||||
"timestamp": "2024-01-01T12:00:00Z"
|
||||
}
|
||||
```
|
||||
|
||||
### System Status
|
||||
|
||||
**Endpoint**: `GET /api/v1/status`
|
||||
|
||||
Detailed system status:
|
||||
|
||||
```bash
|
||||
curl -H "Authorization: Bearer <token>" \
|
||||
http://localhost:8080/api/v1/status
|
||||
```
|
||||
|
||||
**Response:**
|
||||
```json
|
||||
{
|
||||
"api_gateway": "healthy",
|
||||
"inference_model": "healthy",
|
||||
"database": "healthy",
|
||||
"external_apis": {
|
||||
"serper": "healthy"
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
## Error Responses
|
||||
|
||||
Jan Server returns standard HTTP status codes and JSON error responses:
|
||||
|
||||
```json
|
||||
{
|
||||
"error": {
|
||||
"message": "Invalid request format",
|
||||
"type": "invalid_request_error",
|
||||
"code": "invalid_json"
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
### Common Error Codes
|
||||
|
||||
| Status Code | Description |
|
||||
|-------------|-------------|
|
||||
| `400` | Bad Request - Invalid request format |
|
||||
| `401` | Unauthorized - Invalid or missing authentication |
|
||||
| `403` | Forbidden - Insufficient permissions |
|
||||
| `404` | Not Found - Resource not found |
|
||||
| `429` | Too Many Requests - Rate limit exceeded |
|
||||
| `500` | Internal Server Error - Server error |
|
||||
| `503` | Service Unavailable - Service temporarily unavailable |
|
||||
|
||||
## Interactive Documentation
|
||||
|
||||
Jan Server provides interactive Swagger documentation at:
|
||||
|
||||
```
|
||||
http://localhost:8080/api/swagger/index.html#/
|
||||
```
|
||||
|
||||
This interface allows you to:
|
||||
- Browse all available endpoints
|
||||
- Test API calls directly from the browser
|
||||
- View request/response schemas
|
||||
- Generate code samples
|
||||
|
||||
The Swagger documentation is auto-generated from Go code annotations and provides the most up-to-date API reference.
|
||||
|
||||
## Rate Limiting
|
||||
|
||||
API endpoints implement rate limiting to prevent abuse:
|
||||
|
||||
- **Authenticated requests**: 1000 requests per hour per user
|
||||
- **Unauthenticated requests**: 100 requests per hour per IP
|
||||
- **Model inference**: 60 requests per minute per user
|
||||
|
||||
Rate limit headers are included in responses:
|
||||
```
|
||||
X-RateLimit-Limit: 1000
|
||||
X-RateLimit-Remaining: 999
|
||||
X-RateLimit-Reset: 1609459200
|
||||
```
|
||||
|
||||
## SDK and Client Libraries
|
||||
|
||||
### JavaScript/Node.js
|
||||
|
||||
Use the OpenAI JavaScript SDK with Jan Server:
|
||||
|
||||
```javascript
|
||||
import OpenAI from 'openai';
|
||||
|
||||
const openai = new OpenAI({
|
||||
baseURL: 'http://localhost:8080/api/v1',
|
||||
apiKey: 'your-jwt-token'
|
||||
});
|
||||
|
||||
const completion = await openai.chat.completions.create({
|
||||
model: 'jan-v1-4b',
|
||||
messages: [
|
||||
{ role: 'user', content: 'Hello!' }
|
||||
]
|
||||
});
|
||||
```
|
||||
|
||||
### Python
|
||||
|
||||
Use the OpenAI Python SDK:
|
||||
|
||||
```python
|
||||
import openai
|
||||
|
||||
openai.api_base = "http://localhost:8080/api/v1"
|
||||
openai.api_key = "your-jwt-token"
|
||||
|
||||
response = openai.ChatCompletion.create(
|
||||
model="jan-v1-4b",
|
||||
messages=[
|
||||
{"role": "user", "content": "Hello!"}
|
||||
]
|
||||
)
|
||||
```
|
||||
|
||||
### cURL Examples
|
||||
|
||||
Complete cURL examples for common operations:
|
||||
|
||||
```bash
|
||||
# Get models
|
||||
curl http://localhost:8080/api/v1/models
|
||||
|
||||
# Chat completion
|
||||
curl -X POST http://localhost:8080/api/v1/chat/completions \
|
||||
-H "Content-Type: application/json" \
|
||||
-d '{
|
||||
"model": "jan-v1-4b",
|
||||
"messages": [{"role": "user", "content": "Hello"}]
|
||||
}'
|
||||
|
||||
# Streaming chat completion
|
||||
curl -X POST http://localhost:8080/api/v1/chat/completions \
|
||||
-H "Content-Type: application/json" \
|
||||
-d '{
|
||||
"model": "jan-v1-4b",
|
||||
"messages": [{"role": "user", "content": "Tell me a story"}],
|
||||
"stream": true
|
||||
}' \
|
||||
--no-buffer
|
||||
```
|
||||
@ -1,191 +0,0 @@
|
||||
---
|
||||
title: Architecture
|
||||
description: Technical architecture and system design of Jan Server components.
|
||||
---
|
||||
|
||||
## System Overview
|
||||
|
||||
Jan Server implements a microservices architecture on Kubernetes with three core components communicating over HTTP and managed by Helm charts.
|
||||
|
||||
```mermaid
|
||||
graph TD
|
||||
Client[Client/Browser] --> Gateway[jan-api-gateway:8080]
|
||||
Gateway --> Model[jan-inference-model:8101]
|
||||
Gateway --> DB[(PostgreSQL:5432)]
|
||||
Gateway --> Serper[Serper API]
|
||||
Gateway --> OAuth[Google OAuth2]
|
||||
```
|
||||
|
||||
## Components
|
||||
|
||||
### API Gateway (`jan-api-gateway`)
|
||||
|
||||
**Technology Stack:**
|
||||
- **Language**: Go 1.24.6
|
||||
- **Framework**: Gin web framework
|
||||
- **ORM**: GORM with PostgreSQL driver
|
||||
- **DI**: Google Wire for dependency injection
|
||||
- **Documentation**: Swagger/OpenAPI auto-generated
|
||||
|
||||
**Responsibilities:**
|
||||
- HTTP request routing and middleware
|
||||
- User authentication via JWT and OAuth2
|
||||
- Database operations and data persistence
|
||||
- External API integration (Serper, Google OAuth)
|
||||
- OpenAI-compatible API endpoints
|
||||
- Request forwarding to inference service
|
||||
|
||||
**Key Directories:**
|
||||
```
|
||||
application/
|
||||
├── cmd/server/ # Main entry point and DI wiring
|
||||
├── app/ # Core business logic
|
||||
├── config/ # Environment variables and settings
|
||||
└── docs/ # Auto-generated Swagger docs
|
||||
```
|
||||
|
||||
### Inference Model (`jan-inference-model`)
|
||||
|
||||
**Technology Stack:**
|
||||
- **Base Image**: VLLM OpenAI v0.10.0
|
||||
- **Model**: Jan-v1-4B (downloaded from Hugging Face)
|
||||
- **Protocol**: OpenAI-compatible HTTP API
|
||||
- **Features**: Tool calling, reasoning parsing
|
||||
|
||||
**Configuration:**
|
||||
- **Model Path**: `/models/Jan-v1-4B`
|
||||
- **Served Name**: `jan-v1-4b`
|
||||
- **Port**: 8101
|
||||
- **Batch Tokens**: 1024 max
|
||||
- **Tool Parser**: Hermes
|
||||
- **Reasoning Parser**: Qwen3
|
||||
|
||||
**Capabilities:**
|
||||
- Text generation and completion
|
||||
- Tool calling and function execution
|
||||
- Multi-turn conversations
|
||||
- Reasoning and chain-of-thought
|
||||
|
||||
### Database (PostgreSQL)
|
||||
|
||||
**Configuration:**
|
||||
- **Database**: `jan`
|
||||
- **User**: `jan-user`
|
||||
- **Password**: `jan-password`
|
||||
- **Port**: 5432
|
||||
|
||||
**Schema:**
|
||||
- User accounts and authentication
|
||||
- Conversation history
|
||||
- Project and organization management
|
||||
- API keys and access control
|
||||
|
||||
## Data Flow
|
||||
|
||||
### Request Processing
|
||||
|
||||
1. **Client Request**: HTTP request to API gateway on port 8080
|
||||
2. **Authentication**: JWT token validation or OAuth2 flow
|
||||
3. **Request Routing**: Gateway routes to appropriate handler
|
||||
4. **Database Operations**: GORM queries for user data/state
|
||||
5. **Inference Call**: HTTP request to model service on port 8101
|
||||
6. **Response Assembly**: Gateway combines results and returns to client
|
||||
|
||||
### Authentication Flow
|
||||
|
||||
**JWT Authentication:**
|
||||
1. User provides credentials
|
||||
2. Gateway validates against database
|
||||
3. JWT token issued with HMAC-SHA256 signing
|
||||
4. Subsequent requests include JWT in Authorization header
|
||||
|
||||
**OAuth2 Flow:**
|
||||
1. Client redirected to Google OAuth2
|
||||
2. Authorization code returned to redirect URL
|
||||
3. Gateway exchanges code for access token
|
||||
4. User profile retrieved from Google
|
||||
5. Local JWT token issued
|
||||
|
||||
## Deployment Architecture
|
||||
|
||||
### Kubernetes Resources
|
||||
|
||||
**Deployments:**
|
||||
- `jan-api-gateway`: Single replica Go application
|
||||
- `jan-inference-model`: Single replica VLLM server
|
||||
- `postgresql`: StatefulSet with persistent storage
|
||||
|
||||
**Services:**
|
||||
- `jan-api-gateway`: ClusterIP exposing port 8080
|
||||
- `jan-inference-model`: ClusterIP exposing port 8101
|
||||
- `postgresql`: ClusterIP exposing port 5432
|
||||
|
||||
**Configuration:**
|
||||
- Environment variables via Helm values
|
||||
- Secrets for sensitive data (JWT keys, OAuth credentials)
|
||||
- ConfigMaps for application settings
|
||||
|
||||
### Helm Chart Structure
|
||||
|
||||
```
|
||||
charts/
|
||||
├── umbrella-chart/ # Main deployment chart
|
||||
│ ├── Chart.yaml
|
||||
│ ├── values.yaml # Configuration values
|
||||
│ └── Chart.lock
|
||||
└── apps-charts/ # Individual service charts
|
||||
├── jan-api-gateway/
|
||||
└── jan-inference-model/
|
||||
```
|
||||
|
||||
## Security Architecture
|
||||
|
||||
### Authentication Methods
|
||||
- **JWT Tokens**: HMAC-SHA256 signed tokens for API access
|
||||
- **OAuth2**: Google OAuth2 integration for user login
|
||||
- **API Keys**: HMAC-SHA256 signed keys for service access
|
||||
|
||||
### Network Security
|
||||
- **Internal Communication**: Services communicate over Kubernetes cluster network
|
||||
- **External Access**: Only API gateway exposed via port forwarding or ingress
|
||||
- **Database Access**: PostgreSQL accessible only within cluster
|
||||
|
||||
### Data Security
|
||||
- **Secrets Management**: Kubernetes secrets for sensitive configuration
|
||||
- **Environment Variables**: Non-sensitive config via environment variables
|
||||
- **Database Encryption**: Standard PostgreSQL encryption at rest
|
||||
|
||||
Production deployments should implement additional security measures including TLS termination, network policies, and secret rotation.
|
||||
|
||||
## Scalability Considerations
|
||||
|
||||
**Current Limitations:**
|
||||
- Single replica deployments
|
||||
- No horizontal pod autoscaling
|
||||
- Local storage for database
|
||||
|
||||
**Future Enhancements:**
|
||||
- Multi-replica API gateway with load balancing
|
||||
- Horizontal pod autoscaling based on CPU/memory
|
||||
- External database with clustering
|
||||
- Redis caching layer
|
||||
- Message queue for async processing
|
||||
|
||||
## Development Architecture
|
||||
|
||||
### Code Generation
|
||||
- **Swagger**: API documentation generated from Go annotations
|
||||
- **Wire**: Dependency injection code generated from providers
|
||||
- **GORM Gen**: Database model generation from schema
|
||||
|
||||
### Build Process
|
||||
1. **API Gateway**: Multi-stage Docker build with Go compilation
|
||||
2. **Inference Model**: Base VLLM image with model download
|
||||
3. **Helm Charts**: Dependency management and templating
|
||||
4. **Documentation**: Auto-generation during development
|
||||
|
||||
### Local Development
|
||||
- **Hot Reload**: Source code changes reflected without full rebuild
|
||||
- **Database Migrations**: Automated schema updates
|
||||
- **API Testing**: Swagger UI for interactive testing
|
||||
- **Logging**: Structured logging with configurable levels
|
||||
@ -1,263 +0,0 @@
|
||||
---
|
||||
title: Configuration
|
||||
description: Configure Jan Server environment variables, authentication, and external integrations.
|
||||
---
|
||||
|
||||
## Environment Variables
|
||||
|
||||
Jan Server configuration is managed through environment variables defined in the Helm values file at `charts/umbrella-chart/values.yaml`.
|
||||
|
||||
### API Gateway Configuration
|
||||
|
||||
#### Core Settings
|
||||
|
||||
| Variable | Default | Description |
|
||||
|----------|---------|-------------|
|
||||
| `JAN_INFERENCE_MODEL_URL` | `http://jan-server-jan-inference-model:8101` | Internal URL for inference service |
|
||||
|
||||
#### Authentication
|
||||
|
||||
| Variable | Purpose | Format |
|
||||
|----------|---------|--------|
|
||||
| `JWT_SECRET` | JWT token signing | Base64 encoded HMAC-SHA256 key |
|
||||
| `APIKEY_SECRET` | API key signing | Base64 encoded HMAC-SHA256 key |
|
||||
|
||||
The default JWT and API key secrets are for development only. Generate new secrets for production deployments.
|
||||
|
||||
#### OAuth2 Integration
|
||||
|
||||
| Variable | Description |
|
||||
|----------|-------------|
|
||||
| `OAUTH2_GOOGLE_CLIENT_ID` | Google OAuth2 application client ID |
|
||||
| `OAUTH2_GOOGLE_CLIENT_SECRET` | Google OAuth2 application secret |
|
||||
| `OAUTH2_GOOGLE_REDIRECT_URL` | Callback URL for OAuth2 flow |
|
||||
|
||||
#### External APIs
|
||||
|
||||
| Variable | Provider | Purpose |
|
||||
|----------|----------|---------|
|
||||
| `SERPER_API_KEY` | Serper | Web search integration |
|
||||
|
||||
#### Database Connection
|
||||
|
||||
| Variable | Default | Description |
|
||||
|----------|---------|-------------|
|
||||
| `DB_POSTGRESQL_WRITE_DSN` | `host=jan-server-postgresql user=jan-user password=jan-password dbname=jan port=5432 sslmode=disable` | Write database connection |
|
||||
| `DB_POSTGRESQL_READ1_DSN` | `host=jan-server-postgresql user=jan-user password=jan-password dbname=jan port=5432 sslmode=disable` | Read database connection |
|
||||
|
||||
## Helm Configuration
|
||||
|
||||
### Updating Values
|
||||
|
||||
Edit the configuration in `charts/umbrella-chart/values.yaml`:
|
||||
|
||||
```yaml
|
||||
jan-api-gateway:
|
||||
env:
|
||||
- name: SERPER_API_KEY
|
||||
value: your_serper_api_key
|
||||
- name: OAUTH2_GOOGLE_CLIENT_ID
|
||||
value: your_google_client_id
|
||||
- name: OAUTH2_GOOGLE_CLIENT_SECRET
|
||||
value: your_google_client_secret
|
||||
```
|
||||
|
||||
### Applying Changes
|
||||
|
||||
After modifying values, redeploy the application:
|
||||
|
||||
```bash
|
||||
helm upgrade jan-server ./charts/umbrella-chart
|
||||
```
|
||||
|
||||
## Authentication Setup
|
||||
|
||||
### JWT Tokens
|
||||
|
||||
Generate a secure JWT signing key:
|
||||
|
||||
```bash
|
||||
# Generate 256-bit key for HMAC-SHA256
|
||||
openssl rand -base64 32
|
||||
```
|
||||
|
||||
Update the `JWT_SECRET` value in your Helm configuration.
|
||||
|
||||
### API Keys
|
||||
|
||||
Generate a secure API key signing secret:
|
||||
|
||||
```bash
|
||||
# Generate 256-bit key for HMAC-SHA256
|
||||
openssl rand -base64 32
|
||||
```
|
||||
|
||||
Update the `APIKEY_SECRET` value in your Helm configuration.
|
||||
|
||||
### Google OAuth2
|
||||
|
||||
1. **Create Google Cloud Project**
|
||||
- Go to [Google Cloud Console](https://console.cloud.google.com)
|
||||
- Create a new project or select existing
|
||||
|
||||
2. **Enable OAuth2**
|
||||
- Navigate to "APIs & Services" > "Credentials"
|
||||
- Create OAuth2 client ID credentials
|
||||
- Set application type to "Web application"
|
||||
|
||||
3. **Configure Redirect URI**
|
||||
```
|
||||
http://localhost:8080/auth/google/callback
|
||||
```
|
||||
|
||||
4. **Update Configuration**
|
||||
- Set `OAUTH2_GOOGLE_CLIENT_ID` to your client ID
|
||||
- Set `OAUTH2_GOOGLE_CLIENT_SECRET` to your client secret
|
||||
- Set `OAUTH2_GOOGLE_REDIRECT_URL` to your callback URL
|
||||
|
||||
## External Integrations
|
||||
|
||||
### Serper API
|
||||
|
||||
Jan Server integrates with Serper for web search capabilities.
|
||||
|
||||
1. **Get API Key**
|
||||
- Register at [serper.dev](https://serper.dev)
|
||||
- Generate API key from dashboard
|
||||
|
||||
2. **Configure**
|
||||
- Set `SERPER_API_KEY` in Helm values
|
||||
- Redeploy the application
|
||||
|
||||
### Adding New Integrations
|
||||
|
||||
To add new external API integrations:
|
||||
|
||||
1. **Update Helm Values**
|
||||
```yaml
|
||||
jan-api-gateway:
|
||||
env:
|
||||
- name: YOUR_API_KEY
|
||||
value: your_api_key_value
|
||||
```
|
||||
|
||||
2. **Update Go Configuration**
|
||||
|
||||
Add to `config/environment_variables/env.go`:
|
||||
```go
|
||||
YourAPIKey string `env:"YOUR_API_KEY"`
|
||||
```
|
||||
|
||||
3. **Redeploy**
|
||||
```bash
|
||||
helm upgrade jan-server ./charts/umbrella-chart
|
||||
```
|
||||
|
||||
## Database Configuration
|
||||
|
||||
### Connection Settings
|
||||
|
||||
The default PostgreSQL configuration uses:
|
||||
- **Host**: `jan-server-postgresql` (Kubernetes service name)
|
||||
- **Database**: `jan`
|
||||
- **User**: `jan-user`
|
||||
- **Password**: `jan-password`
|
||||
- **Port**: `5432`
|
||||
- **SSL**: Disabled (development only)
|
||||
|
||||
### Production Database
|
||||
|
||||
For production deployments:
|
||||
|
||||
1. **External Database**
|
||||
- Use managed PostgreSQL service (AWS RDS, Google Cloud SQL)
|
||||
- Update DSN variables with external connection details
|
||||
|
||||
2. **SSL/TLS**
|
||||
- Enable `sslmode=require` in connection strings
|
||||
- Configure certificate validation
|
||||
|
||||
3. **Connection Pooling**
|
||||
- Consider using connection pooler (PgBouncer, pgpool-II)
|
||||
- Configure appropriate pool sizes
|
||||
|
||||
## Model Configuration
|
||||
|
||||
The inference model service is configured via Docker CMD parameters:
|
||||
|
||||
```dockerfile
|
||||
CMD ["--model", "/models/Jan-v1-4B", \
|
||||
"--served-model-name", "jan-v1-4b", \
|
||||
"--host", "0.0.0.0", \
|
||||
"--port", "8101", \
|
||||
"--max-num-batched-tokens", "1024", \
|
||||
"--enable-auto-tool-choice", \
|
||||
"--tool-call-parser", "hermes", \
|
||||
"--reasoning-parser", "qwen3"]
|
||||
```
|
||||
|
||||
### Model Parameters
|
||||
|
||||
| Parameter | Value | Description |
|
||||
|-----------|-------|-------------|
|
||||
| `--model` | `/models/Jan-v1-4B` | Path to model files |
|
||||
| `--served-model-name` | `jan-v1-4b` | API model identifier |
|
||||
| `--max-num-batched-tokens` | `1024` | Maximum tokens per batch |
|
||||
| `--tool-call-parser` | `hermes` | Tool calling format |
|
||||
| `--reasoning-parser` | `qwen3` | Reasoning output format |
|
||||
|
||||
Model configuration changes require rebuilding the inference Docker image. This will be configurable via environment variables in future releases.
|
||||
|
||||
## Resource Configuration
|
||||
|
||||
### Kubernetes Resources
|
||||
|
||||
Current deployments use default resource limits. For production:
|
||||
|
||||
```yaml
|
||||
jan-api-gateway:
|
||||
resources:
|
||||
requests:
|
||||
cpu: 100m
|
||||
memory: 128Mi
|
||||
limits:
|
||||
cpu: 500m
|
||||
memory: 512Mi
|
||||
|
||||
jan-inference-model:
|
||||
resources:
|
||||
requests:
|
||||
cpu: 1000m
|
||||
memory: 4Gi
|
||||
limits:
|
||||
cpu: 4000m
|
||||
memory: 8Gi
|
||||
```
|
||||
|
||||
### Storage
|
||||
|
||||
PostgreSQL uses default Kubernetes storage. For production:
|
||||
|
||||
```yaml
|
||||
postgresql:
|
||||
persistence:
|
||||
enabled: true
|
||||
size: 20Gi
|
||||
storageClass: fast-ssd
|
||||
```
|
||||
|
||||
## Logging Configuration
|
||||
|
||||
Configure logging levels via environment variables:
|
||||
|
||||
```yaml
|
||||
jan-api-gateway:
|
||||
env:
|
||||
- name: LOG_LEVEL
|
||||
value: info
|
||||
- name: LOG_FORMAT
|
||||
value: json
|
||||
```
|
||||
|
||||
Available log levels: `debug`, `info`, `warn`, `error`
|
||||
Available formats: `text`, `json`
|
||||
@ -1,445 +0,0 @@
|
||||
---
|
||||
title: Development
|
||||
description: Development setup, workflow, and contribution guidelines for Jan Server.
|
||||
---
|
||||
|
||||
## Development Setup
|
||||
|
||||
### Prerequisites
|
||||
|
||||
- **Go**: 1.24.6 or later
|
||||
- **Docker**: For containerization
|
||||
- **minikube**: Local Kubernetes development
|
||||
- **Helm**: Package management
|
||||
- **Make**: Build automation
|
||||
|
||||
### Initial Setup
|
||||
|
||||
|
||||
1. **Clone Repository**
|
||||
```bash
|
||||
git clone https://github.com/menloresearch/jan-server
|
||||
cd jan-server
|
||||
```
|
||||
|
||||
2. **Install Development Tools**
|
||||
```bash
|
||||
cd apps/jan-api-gateway/application
|
||||
make install
|
||||
```
|
||||
|
||||
3. **Generate Code**
|
||||
```bash
|
||||
make setup
|
||||
```
|
||||
|
||||
4. **Start Development Environment**
|
||||
```bash
|
||||
# From project root
|
||||
./scripts/run.sh
|
||||
```
|
||||
|
||||
## API Gateway Development
|
||||
|
||||
### Project Structure
|
||||
|
||||
```
|
||||
apps/jan-api-gateway/application/
|
||||
├── cmd/server/ # Entry point and dependency injection
|
||||
│ ├── server.go # Main server setup
|
||||
│ ├── wire.go # DI configuration
|
||||
│ └── wire_gen.go # Generated DI code
|
||||
├── app/ # Core application logic
|
||||
│ ├── domain/ # Business entities
|
||||
│ ├── repository/ # Data access layer
|
||||
│ ├── service/ # Business logic
|
||||
│ └── handler/ # HTTP handlers
|
||||
├── config/ # Configuration management
|
||||
└── docs/ # Generated API documentation
|
||||
```
|
||||
|
||||
### Build Commands
|
||||
|
||||
```bash
|
||||
# Install development dependencies
|
||||
make install
|
||||
|
||||
# Generate API documentation
|
||||
make doc
|
||||
|
||||
# Generate dependency injection code
|
||||
make wire
|
||||
|
||||
# Complete setup (doc + wire)
|
||||
make setup
|
||||
|
||||
# Build application
|
||||
go build -o jan-api-gateway ./cmd/server
|
||||
```
|
||||
|
||||
### Code Generation
|
||||
|
||||
Jan Server uses code generation for several components:
|
||||
|
||||
**Swagger Documentation:**
|
||||
```bash
|
||||
# Generates docs/swagger.json and docs/swagger.yaml
|
||||
swag init --parseDependency -g cmd/server/server.go -o docs
|
||||
```
|
||||
|
||||
**Dependency Injection:**
|
||||
```bash
|
||||
# Generates wire_gen.go from wire.go providers
|
||||
wire ./cmd/server
|
||||
```
|
||||
|
||||
**Database Models:**
|
||||
```bash
|
||||
# Generate GORM models (when schema changes)
|
||||
go run cmd/codegen/gorm/gorm.go
|
||||
```
|
||||
|
||||
### Local Development
|
||||
|
||||
#### Running API Gateway Locally
|
||||
|
||||
```bash
|
||||
cd apps/jan-api-gateway/application
|
||||
|
||||
# Set environment variables
|
||||
export JAN_INFERENCE_MODEL_URL=http://localhost:8101
|
||||
export JWT_SECRET=your-jwt-secret
|
||||
export DB_POSTGRESQL_WRITE_DSN="host=localhost user=jan-user password=jan-password dbname=jan port=5432 sslmode=disable"
|
||||
|
||||
# Run the server
|
||||
go run ./cmd/server
|
||||
```
|
||||
|
||||
#### Database Setup
|
||||
|
||||
For local development, you can run PostgreSQL directly:
|
||||
|
||||
```bash
|
||||
# Using Docker
|
||||
docker run -d \
|
||||
--name jan-postgres \
|
||||
-e POSTGRES_DB=jan \
|
||||
-e POSTGRES_USER=jan-user \
|
||||
-e POSTGRES_PASSWORD=jan-password \
|
||||
-p 5432:5432 \
|
||||
postgres:14
|
||||
```
|
||||
|
||||
## Testing
|
||||
|
||||
### Running Tests
|
||||
|
||||
```bash
|
||||
# Run all tests
|
||||
go test ./...
|
||||
|
||||
# Run tests with coverage
|
||||
go test -cover ./...
|
||||
|
||||
# Run specific test package
|
||||
go test ./app/service/...
|
||||
```
|
||||
|
||||
### Test Structure
|
||||
|
||||
```
|
||||
app/
|
||||
├── service/
|
||||
│ ├── auth_service.go
|
||||
│ ├── auth_service_test.go
|
||||
│ ├── conversation_service.go
|
||||
│ └── conversation_service_test.go
|
||||
└── handler/
|
||||
├── auth_handler.go
|
||||
├── auth_handler_test.go
|
||||
├── chat_handler.go
|
||||
└── chat_handler_test.go
|
||||
```
|
||||
|
||||
### Writing Tests
|
||||
|
||||
Example service test:
|
||||
|
||||
```go
|
||||
func TestAuthService_ValidateToken(t *testing.T) {
|
||||
// Setup
|
||||
service := NewAuthService(mockRepo, mockConfig)
|
||||
|
||||
// Test cases
|
||||
tests := []struct {
|
||||
name string
|
||||
token string
|
||||
expectValid bool
|
||||
expectError bool
|
||||
}{
|
||||
{"valid token", "valid.jwt.token", true, false},
|
||||
{"invalid token", "invalid.token", false, true},
|
||||
}
|
||||
|
||||
for _, tt := range tests {
|
||||
t.Run(tt.name, func(t *testing.T) {
|
||||
valid, err := service.ValidateToken(tt.token)
|
||||
assert.Equal(t, tt.expectValid, valid)
|
||||
assert.Equal(t, tt.expectError, err != nil)
|
||||
})
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
## Docker Development
|
||||
|
||||
### Building Images
|
||||
|
||||
```bash
|
||||
# Build API gateway
|
||||
docker build -t jan-api-gateway:dev ./apps/jan-api-gateway
|
||||
|
||||
# Build inference model
|
||||
docker build -t jan-inference-model:dev ./apps/jan-inference-model
|
||||
```
|
||||
|
||||
### Development Compose
|
||||
|
||||
For local development without Kubernetes:
|
||||
|
||||
```yaml
|
||||
# docker-compose.dev.yml
|
||||
version: '3.8'
|
||||
services:
|
||||
postgres:
|
||||
image: postgres:14
|
||||
environment:
|
||||
POSTGRES_DB: jan
|
||||
POSTGRES_USER: jan-user
|
||||
POSTGRES_PASSWORD: jan-password
|
||||
ports:
|
||||
- "5432:5432"
|
||||
|
||||
api-gateway:
|
||||
build: ./apps/jan-api-gateway
|
||||
ports:
|
||||
- "8080:8080"
|
||||
environment:
|
||||
- JAN_INFERENCE_MODEL_URL=http://inference-model:8101
|
||||
- DB_POSTGRESQL_WRITE_DSN=host=postgres user=jan-user password=jan-password dbname=jan port=5432 sslmode=disable
|
||||
depends_on:
|
||||
- postgres
|
||||
|
||||
inference-model:
|
||||
build: ./apps/jan-inference-model
|
||||
ports:
|
||||
- "8101:8101"
|
||||
```
|
||||
|
||||
## Debugging
|
||||
|
||||
### Go Debugging
|
||||
|
||||
For VS Code debugging, add to `.vscode/launch.json`:
|
||||
|
||||
```json
|
||||
{
|
||||
"version": "0.2.0",
|
||||
"configurations": [
|
||||
{
|
||||
"name": "Launch Jan API Gateway",
|
||||
"type": "go",
|
||||
"request": "launch",
|
||||
"mode": "auto",
|
||||
"program": "${workspaceFolder}/apps/jan-api-gateway/application/cmd/server",
|
||||
"env": {
|
||||
"JAN_INFERENCE_MODEL_URL": "http://localhost:8101",
|
||||
"JWT_SECRET": "development-secret"
|
||||
}
|
||||
}
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
### Application Logs
|
||||
|
||||
```bash
|
||||
# View API gateway logs
|
||||
kubectl logs deployment/jan-server-jan-api-gateway -f
|
||||
|
||||
# View inference model logs
|
||||
kubectl logs deployment/jan-server-jan-inference-model -f
|
||||
|
||||
# View PostgreSQL logs
|
||||
kubectl logs statefulset/jan-server-postgresql -f
|
||||
```
|
||||
|
||||
### Log Levels
|
||||
|
||||
Set log level via environment variable:
|
||||
|
||||
```bash
|
||||
export LOG_LEVEL=debug # debug, info, warn, error
|
||||
```
|
||||
|
||||
## Code Style and Standards
|
||||
|
||||
### Go Standards
|
||||
|
||||
- Follow [Go Code Review Comments](https://go.dev/wiki/CodeReviewComments)
|
||||
- Use `gofmt` for formatting
|
||||
- Run `go vet` for static analysis
|
||||
- Use meaningful variable and function names
|
||||
|
||||
### API Standards
|
||||
|
||||
- RESTful endpoint design
|
||||
- OpenAPI/Swagger annotations for all endpoints
|
||||
- Consistent error response format
|
||||
- Proper HTTP status codes
|
||||
|
||||
### Git Workflow
|
||||
|
||||
```bash
|
||||
# Create feature branch
|
||||
git checkout -b feature/your-feature-name
|
||||
|
||||
# Make changes and commit
|
||||
git add .
|
||||
git commit -m "feat: add new authentication endpoint"
|
||||
|
||||
# Push and create PR
|
||||
git push origin feature/your-feature-name
|
||||
```
|
||||
|
||||
### Commit Message Format
|
||||
|
||||
Follow conventional commits:
|
||||
|
||||
```
|
||||
feat: add new feature
|
||||
fix: resolve bug in authentication
|
||||
docs: update API documentation
|
||||
test: add unit tests for service layer
|
||||
refactor: improve error handling
|
||||
```
|
||||
|
||||
## Performance Testing
|
||||
|
||||
### Load Testing
|
||||
|
||||
Use [k6](https://k6.io) for API load testing:
|
||||
|
||||
```javascript
|
||||
// load-test.js
|
||||
import http from 'k6/http';
|
||||
|
||||
export default function () {
|
||||
const response = http.post('http://localhost:8080/api/v1/chat/completions', {
|
||||
model: 'jan-v1-4b',
|
||||
messages: [
|
||||
{ role: 'user', content: 'Hello!' }
|
||||
]
|
||||
}, {
|
||||
headers: {
|
||||
'Content-Type': 'application/json',
|
||||
'Authorization': 'Bearer your-token'
|
||||
}
|
||||
});
|
||||
|
||||
check(response, {
|
||||
'status is 200': (r) => r.status === 200,
|
||||
'response time < 5000ms': (r) => r.timings.duration < 5000,
|
||||
});
|
||||
}
|
||||
```
|
||||
|
||||
Run load test:
|
||||
```bash
|
||||
k6 run --vus 10 --duration 30s load-test.js
|
||||
```
|
||||
|
||||
### Memory Profiling
|
||||
|
||||
Enable Go profiling endpoints:
|
||||
|
||||
```go
|
||||
import _ "net/http/pprof"
|
||||
|
||||
// In main.go
|
||||
go func() {
|
||||
log.Println(http.ListenAndServe("localhost:6060", nil))
|
||||
}()
|
||||
```
|
||||
|
||||
Profile memory usage:
|
||||
```bash
|
||||
go tool pprof http://localhost:6060/debug/pprof/heap
|
||||
```
|
||||
|
||||
## Contributing
|
||||
|
||||
### Pull Request Process
|
||||
|
||||
1. **Fork the repository**
|
||||
2. **Create feature branch** from `main`
|
||||
3. **Make changes** following code standards
|
||||
4. **Add tests** for new functionality
|
||||
5. **Update documentation** if needed
|
||||
6. **Submit pull request** with clear description
|
||||
|
||||
### Code Review Checklist
|
||||
|
||||
- [ ] Code follows Go standards
|
||||
- [ ] Tests added for new features
|
||||
- [ ] Documentation updated
|
||||
- [ ] API endpoints have Swagger annotations
|
||||
- [ ] No breaking changes without version bump
|
||||
- [ ] Security considerations addressed
|
||||
|
||||
### Issues and Bug Reports
|
||||
|
||||
When reporting bugs, include:
|
||||
|
||||
- **Environment**: OS, Go version, minikube version
|
||||
- **Steps to reproduce**: Clear, minimal reproduction steps
|
||||
- **Expected behavior**: What should happen
|
||||
- **Actual behavior**: What actually happens
|
||||
- **Logs**: Relevant error messages or logs
|
||||
|
||||
For security issues, please report privately to the maintainers instead of creating public issues.
|
||||
|
||||
## Release Process
|
||||
|
||||
### Version Management
|
||||
|
||||
Jan Server uses semantic versioning (semver):
|
||||
|
||||
- **Major**: Breaking changes
|
||||
- **Minor**: New features, backward compatible
|
||||
- **Patch**: Bug fixes, backward compatible
|
||||
|
||||
### Building Releases
|
||||
|
||||
```bash
|
||||
# Tag release
|
||||
git tag -a v1.2.3 -m "Release v1.2.3"
|
||||
|
||||
# Build release images
|
||||
docker build -t jan-api-gateway:v1.2.3 ./apps/jan-api-gateway
|
||||
docker build -t jan-inference-model:v1.2.3 ./apps/jan-inference-model
|
||||
|
||||
# Push tags
|
||||
git push origin v1.2.3
|
||||
```
|
||||
|
||||
### Deployment
|
||||
|
||||
Production deployments follow the same Helm chart structure:
|
||||
|
||||
```bash
|
||||
# Deploy specific version
|
||||
helm install jan-server ./charts/umbrella-chart \
|
||||
--set jan-api-gateway.image.tag=v1.2.3 \
|
||||
--set jan-inference-model.image.tag=v1.2.3
|
||||
```
|
||||
@ -1,39 +0,0 @@
|
||||
---
|
||||
title: Jan Server
|
||||
description: Self-hosted AI infrastructure running the Jan platform on Kubernetes.
|
||||
keywords:
|
||||
[
|
||||
Jan Server,
|
||||
self-hosted AI,
|
||||
Kubernetes deployment,
|
||||
Docker containers,
|
||||
AI inference,
|
||||
local LLM server,
|
||||
VLLM,
|
||||
Go API gateway,
|
||||
Jan-v1 model
|
||||
]
|
||||
---
|
||||
|
||||
## Self-Hosted Jan Platform
|
||||
|
||||
Jan Server deploys the Jan AI platform on your own infrastructure using Kubernetes. It provides a complete AI inference stack with API gateway, model serving, and data persistence.
|
||||
|
||||
Jan Server is in early development. APIs and deployment methods may change.
|
||||
|
||||
## Architecture Overview
|
||||
|
||||
Jan Server consists of two main components:
|
||||
|
||||
- **API Gateway**: Go application handling authentication, web requests, and external integrations
|
||||
- **Inference Model**: VLLM server running the Jan-v1-4B model for AI inference
|
||||
- **PostgreSQL**: Database for user data, conversations, and system state
|
||||
|
||||
## Key Features
|
||||
|
||||
- **Kubernetes Native**: Deploys via Helm charts with minikube support
|
||||
- **Jan-v1 Model**: 4B parameter model optimized for reasoning and tool use
|
||||
- **OpenAI Compatible API**: Standard endpoints for integration
|
||||
- **Authentication**: JWT tokens and OAuth2 Google integration
|
||||
- **External Integrations**: Serper API for web search capabilities
|
||||
- **Development Ready**: Local development environment with hot reload
|
||||
@ -1,151 +0,0 @@
|
||||
---
|
||||
title: Installation
|
||||
description: Install and deploy Jan Server on Kubernetes using minikube and Helm.
|
||||
---
|
||||
|
||||
# Prerequisites
|
||||
|
||||
Jan Server requires the following tools installed on your system:
|
||||
|
||||
- **Docker**: For building container images
|
||||
- **minikube**: Local Kubernetes cluster for development
|
||||
- **Helm**: Package manager for Kubernetes applications
|
||||
- **kubectl**: Kubernetes command-line tool (installed with minikube)
|
||||
|
||||
Jan Server currently supports minikube for local development. Production Kubernetes deployments are planned for future releases.
|
||||
|
||||
## Quick Start
|
||||
|
||||
|
||||
1. **Clone the repository**
|
||||
```bash
|
||||
git clone https://github.com/menloresearch/jan-server
|
||||
cd jan-server
|
||||
```
|
||||
|
||||
2. **Start minikube**
|
||||
```bash
|
||||
minikube start
|
||||
```
|
||||
|
||||
3. **Configure Docker environment**
|
||||
```bash
|
||||
eval $(minikube docker-env)
|
||||
alias kubectl="minikube kubectl --"
|
||||
```
|
||||
|
||||
4. **Deploy Jan Server**
|
||||
```bash
|
||||
./scripts/run.sh
|
||||
```
|
||||
|
||||
5. **Access the API**
|
||||
|
||||
The script automatically forwards port 8080. Access the Swagger UI at:
|
||||
```
|
||||
http://localhost:8080/api/swagger/index.html#/
|
||||
```
|
||||
|
||||
|
||||
## Manual Installation
|
||||
|
||||
### Build Docker Images
|
||||
|
||||
Build both required Docker images:
|
||||
|
||||
```bash
|
||||
# Build API Gateway
|
||||
docker build -t jan-api-gateway:latest ./apps/jan-api-gateway
|
||||
|
||||
# Build Inference Model
|
||||
docker build -t jan-inference-model:latest ./apps/jan-inference-model
|
||||
```
|
||||
|
||||
The inference model image downloads the Jan-v1-4B model from Hugging Face during build. This requires an internet connection and several GB of download.
|
||||
|
||||
### Deploy with Helm
|
||||
|
||||
Install the Helm chart:
|
||||
|
||||
```bash
|
||||
# Update Helm dependencies
|
||||
helm dependency update ./charts/umbrella-chart
|
||||
|
||||
# Install Jan Server
|
||||
helm install jan-server ./charts/umbrella-chart
|
||||
```
|
||||
|
||||
### Port Forwarding
|
||||
|
||||
Forward the API gateway port to access from your local machine:
|
||||
|
||||
```bash
|
||||
kubectl port-forward svc/jan-server-jan-api-gateway 8080:8080
|
||||
```
|
||||
|
||||
## Verify Installation
|
||||
|
||||
Check that all pods are running:
|
||||
|
||||
```bash
|
||||
kubectl get pods
|
||||
```
|
||||
|
||||
Expected output:
|
||||
```
|
||||
NAME READY STATUS RESTARTS
|
||||
jan-server-jan-api-gateway-xxx 1/1 Running 0
|
||||
jan-server-jan-inference-model-xxx 1/1 Running 0
|
||||
jan-server-postgresql-0 1/1 Running 0
|
||||
```
|
||||
|
||||
Test the API gateway:
|
||||
```bash
|
||||
curl http://localhost:8080/health
|
||||
```
|
||||
|
||||
## Uninstalling
|
||||
|
||||
To remove Jan Server:
|
||||
|
||||
```bash
|
||||
helm uninstall jan-server
|
||||
```
|
||||
|
||||
To stop minikube:
|
||||
|
||||
```bash
|
||||
minikube stop
|
||||
```
|
||||
|
||||
## Troubleshooting
|
||||
|
||||
### Common Issues
|
||||
|
||||
**Pods in `ImagePullBackOff` state**
|
||||
- Ensure Docker images were built in the minikube environment
|
||||
- Run `eval $(minikube docker-env)` before building images
|
||||
|
||||
**Port forwarding connection refused**
|
||||
- Verify the service is running: `kubectl get svc`
|
||||
- Check pod status: `kubectl get pods`
|
||||
- Review logs: `kubectl logs deployment/jan-server-jan-api-gateway`
|
||||
|
||||
**Inference model download fails**
|
||||
- Ensure internet connectivity during Docker build
|
||||
- The Jan-v1-4B model is approximately 2.4GB
|
||||
|
||||
### Resource Requirements
|
||||
|
||||
**Minimum System Requirements:**
|
||||
- 8GB RAM
|
||||
- 20GB free disk space
|
||||
- 4 CPU cores
|
||||
|
||||
**Recommended System Requirements:**
|
||||
- 16GB RAM
|
||||
- 50GB free disk space
|
||||
- 8 CPU cores
|
||||
- GPU support (for faster inference)
|
||||
|
||||
The inference model requires significant memory. Ensure your minikube cluster has adequate resources allocated.
|
||||
@ -1,8 +1,4 @@
|
||||
{
|
||||
"-- Switcher": {
|
||||
"type": "separator",
|
||||
"title": "Switcher"
|
||||
},
|
||||
"index": {
|
||||
"type": "page",
|
||||
"title": "Jan Overview"
|
||||
@ -10,9 +6,5 @@
|
||||
"desktop": {
|
||||
"type": "page",
|
||||
"title": "Jan Desktop"
|
||||
},
|
||||
"server": {
|
||||
"type": "page",
|
||||
"title": "Jan Server"
|
||||
}
|
||||
}
|
||||
|
||||
@ -3,10 +3,8 @@ import { useEffect } from 'react'
|
||||
|
||||
export default function DocsIndex() {
|
||||
const router = useRouter()
|
||||
|
||||
useEffect(() => {
|
||||
router.replace('/docs/desktop')
|
||||
}, [router])
|
||||
|
||||
return null
|
||||
}
|
||||
@ -1,31 +0,0 @@
|
||||
{
|
||||
"index": {
|
||||
"type": "page",
|
||||
"display": "hidden"
|
||||
},
|
||||
"get-started-separator": {
|
||||
"title": "Get Started",
|
||||
"type": "separator"
|
||||
},
|
||||
"overview": "Overview",
|
||||
"installation": "Installation",
|
||||
"configuration": "Configuration",
|
||||
"api-reference-separator": {
|
||||
"title": "API Reference",
|
||||
"type": "separator"
|
||||
},
|
||||
"api-reference": "Introduction",
|
||||
"api-reference-authentication": "Authentication",
|
||||
"api-reference-chat": "Completions API",
|
||||
"api-reference-jan-responses": "Responses API",
|
||||
"api-reference-chat-conversations": "Chat Conversations",
|
||||
"api-reference-conversations": "Conversations API",
|
||||
"api-reference-administration": "Administration API",
|
||||
"api-reference-jan-server": "Server API",
|
||||
"resources-separator": {
|
||||
"title": "Resources",
|
||||
"type": "separator"
|
||||
},
|
||||
"architecture": "Architecture",
|
||||
"development": "Development"
|
||||
}
|
||||
@ -1,629 +0,0 @@
|
||||
---
|
||||
title: Organizations API
|
||||
description: Multi-tenant organization management endpoints for admin API keys, invites, and projects.
|
||||
---
|
||||
|
||||
## Overview
|
||||
|
||||
The Organizations API provides comprehensive endpoints for managing multi-tenant organizations, including admin API key management, organization invites, project creation, and project-level API key management. This API is essential for enterprise deployments and multi-user environments.
|
||||
|
||||
## Endpoints
|
||||
|
||||
### Admin API Keys
|
||||
|
||||
#### List Admin API Keys
|
||||
|
||||
**Endpoint**: `GET /v1/organization/admin_api_keys`
|
||||
|
||||
Retrieves a paginated list of admin API keys for the organization.
|
||||
|
||||
**Query Parameters:**
|
||||
- `limit` (integer, optional): Number of keys to return (1-100, default: 20)
|
||||
- `offset` (integer, optional): Number of keys to skip (default: 0)
|
||||
|
||||
**Response:**
|
||||
```json
|
||||
{
|
||||
"api_keys": [
|
||||
{
|
||||
"id": "ak_123",
|
||||
"name": "Production Admin Key",
|
||||
"created_at": "2024-01-01T12:00:00Z",
|
||||
"last_used": "2024-01-01T15:30:00Z",
|
||||
"permissions": ["admin", "read", "write"],
|
||||
"is_active": true
|
||||
}
|
||||
],
|
||||
"total": 1,
|
||||
"limit": 20,
|
||||
"offset": 0
|
||||
}
|
||||
```
|
||||
|
||||
**Example:**
|
||||
```bash
|
||||
curl -H "Authorization: Bearer <admin_token>" \
|
||||
"http://localhost:8080/v1/organization/admin_api_keys?limit=10"
|
||||
```
|
||||
|
||||
#### Create Admin API Key
|
||||
|
||||
**Endpoint**: `POST /v1/organization/admin_api_keys`
|
||||
|
||||
Creates a new admin API key for the organization.
|
||||
|
||||
**Request Body:**
|
||||
```json
|
||||
{
|
||||
"name": "Development Admin Key",
|
||||
"permissions": ["admin", "read", "write"],
|
||||
"expires_at": "2024-12-31T23:59:59Z"
|
||||
}
|
||||
```
|
||||
|
||||
**Parameters:**
|
||||
- `name` (string, required): Human-readable name for the API key
|
||||
- `permissions` (array, required): List of permissions for the key
|
||||
- `expires_at` (string, optional): Expiration date (ISO 8601 format)
|
||||
|
||||
**Response:**
|
||||
```json
|
||||
{
|
||||
"id": "ak_456",
|
||||
"name": "Development Admin Key",
|
||||
"key": "jan_ak_1234567890abcdef",
|
||||
"created_at": "2024-01-01T12:00:00Z",
|
||||
"expires_at": "2024-12-31T23:59:59Z",
|
||||
"permissions": ["admin", "read", "write"],
|
||||
"is_active": true
|
||||
}
|
||||
```
|
||||
|
||||
**Example:**
|
||||
```bash
|
||||
curl -X POST http://localhost:8080/v1/organization/admin_api_keys \
|
||||
-H "Authorization: Bearer <admin_token>" \
|
||||
-H "Content-Type: application/json" \
|
||||
-d '{
|
||||
"name": "Development Admin Key",
|
||||
"permissions": ["admin", "read", "write"]
|
||||
}'
|
||||
```
|
||||
|
||||
#### Get Admin API Key
|
||||
|
||||
**Endpoint**: `GET /v1/organization/admin_api_keys/{id}`
|
||||
|
||||
Retrieves details of a specific admin API key.
|
||||
|
||||
**Path Parameters:**
|
||||
- `id` (string, required): The API key ID
|
||||
|
||||
**Response:**
|
||||
```json
|
||||
{
|
||||
"id": "ak_123",
|
||||
"name": "Production Admin Key",
|
||||
"created_at": "2024-01-01T12:00:00Z",
|
||||
"last_used": "2024-01-01T15:30:00Z",
|
||||
"expires_at": "2024-12-31T23:59:59Z",
|
||||
"permissions": ["admin", "read", "write"],
|
||||
"is_active": true
|
||||
}
|
||||
```
|
||||
|
||||
**Example:**
|
||||
```bash
|
||||
curl -H "Authorization: Bearer <admin_token>" \
|
||||
http://localhost:8080/v1/organization/admin_api_keys/ak_123
|
||||
```
|
||||
|
||||
#### Delete Admin API Key
|
||||
|
||||
**Endpoint**: `DELETE /v1/organization/admin_api_keys/{id}`
|
||||
|
||||
Permanently deletes an admin API key.
|
||||
|
||||
**Path Parameters:**
|
||||
- `id` (string, required): The API key ID
|
||||
|
||||
**Response:**
|
||||
```
|
||||
204 No Content
|
||||
```
|
||||
|
||||
**Example:**
|
||||
```bash
|
||||
curl -X DELETE http://localhost:8080/v1/organization/admin_api_keys/ak_123 \
|
||||
-H "Authorization: Bearer <admin_token>"
|
||||
```
|
||||
|
||||
### Organization Invites
|
||||
|
||||
#### List Organization Invites
|
||||
|
||||
**Endpoint**: `GET /v1/organization/invites`
|
||||
|
||||
Retrieves a paginated list of organization invites.
|
||||
|
||||
**Query Parameters:**
|
||||
- `limit` (integer, optional): Number of invites to return (1-100, default: 20)
|
||||
- `offset` (integer, optional): Number of invites to skip (default: 0)
|
||||
- `status` (string, optional): Filter by status - "pending", "accepted", "expired"
|
||||
|
||||
**Response:**
|
||||
```json
|
||||
{
|
||||
"invites": [
|
||||
{
|
||||
"id": "inv_123",
|
||||
"email": "user@example.com",
|
||||
"role": "member",
|
||||
"status": "pending",
|
||||
"created_at": "2024-01-01T12:00:00Z",
|
||||
"expires_at": "2024-01-08T12:00:00Z",
|
||||
"invited_by": "admin@example.com"
|
||||
}
|
||||
],
|
||||
"total": 1,
|
||||
"limit": 20,
|
||||
"offset": 0
|
||||
}
|
||||
```
|
||||
|
||||
**Example:**
|
||||
```bash
|
||||
curl -H "Authorization: Bearer <admin_token>" \
|
||||
"http://localhost:8080/v1/organization/invites?status=pending"
|
||||
```
|
||||
|
||||
#### Create Invite
|
||||
|
||||
**Endpoint**: `POST /v1/organization/invites`
|
||||
|
||||
Creates a new organization invite.
|
||||
|
||||
**Request Body:**
|
||||
```json
|
||||
{
|
||||
"email": "newuser@example.com",
|
||||
"role": "member",
|
||||
"expires_in_days": 7,
|
||||
"message": "Welcome to our organization!"
|
||||
}
|
||||
```
|
||||
|
||||
**Parameters:**
|
||||
- `email` (string, required): Email address of the invitee
|
||||
- `role` (string, required): Role for the invitee - "admin", "member", "viewer"
|
||||
- `expires_in_days` (integer, optional): Days until invite expires (default: 7)
|
||||
- `message` (string, optional): Personal message for the invitee
|
||||
|
||||
**Response:**
|
||||
```json
|
||||
{
|
||||
"id": "inv_456",
|
||||
"email": "newuser@example.com",
|
||||
"role": "member",
|
||||
"status": "pending",
|
||||
"created_at": "2024-01-01T12:00:00Z",
|
||||
"expires_at": "2024-01-08T12:00:00Z",
|
||||
"invited_by": "admin@example.com",
|
||||
"invite_url": "https://app.jan.ai/invite/inv_456"
|
||||
}
|
||||
```
|
||||
|
||||
**Example:**
|
||||
```bash
|
||||
curl -X POST http://localhost:8080/v1/organization/invites \
|
||||
-H "Authorization: Bearer <admin_token>" \
|
||||
-H "Content-Type: application/json" \
|
||||
-d '{
|
||||
"email": "newuser@example.com",
|
||||
"role": "member",
|
||||
"expires_in_days": 7,
|
||||
"message": "Welcome to our organization!"
|
||||
}'
|
||||
```
|
||||
|
||||
#### Retrieve Invite
|
||||
|
||||
**Endpoint**: `GET /v1/organization/invites/{invite_id}`
|
||||
|
||||
Retrieves details of a specific invite.
|
||||
|
||||
**Path Parameters:**
|
||||
- `invite_id` (string, required): The invite ID
|
||||
|
||||
**Response:**
|
||||
```json
|
||||
{
|
||||
"id": "inv_123",
|
||||
"email": "user@example.com",
|
||||
"role": "member",
|
||||
"status": "pending",
|
||||
"created_at": "2024-01-01T12:00:00Z",
|
||||
"expires_at": "2024-01-08T12:00:00Z",
|
||||
"invited_by": "admin@example.com",
|
||||
"organization": {
|
||||
"name": "Acme Corp",
|
||||
"domain": "acme.com"
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
**Example:**
|
||||
```bash
|
||||
curl http://localhost:8080/v1/organization/invites/inv_123
|
||||
```
|
||||
|
||||
#### Delete Invite
|
||||
|
||||
**Endpoint**: `DELETE /v1/organization/invites/{invite_id}`
|
||||
|
||||
Cancels and deletes an organization invite.
|
||||
|
||||
**Path Parameters:**
|
||||
- `invite_id` (string, required): The invite ID
|
||||
|
||||
**Response:**
|
||||
```
|
||||
204 No Content
|
||||
```
|
||||
|
||||
**Example:**
|
||||
```bash
|
||||
curl -X DELETE http://localhost:8080/v1/organization/invites/inv_123 \
|
||||
-H "Authorization: Bearer <admin_token>"
|
||||
```
|
||||
|
||||
### Projects
|
||||
|
||||
#### List Projects
|
||||
|
||||
**Endpoint**: `GET /v1/organization/projects`
|
||||
|
||||
Retrieves a paginated list of organization projects.
|
||||
|
||||
**Query Parameters:**
|
||||
- `limit` (integer, optional): Number of projects to return (1-100, default: 20)
|
||||
- `offset` (integer, optional): Number of projects to skip (default: 0)
|
||||
- `status` (string, optional): Filter by status - "active", "archived"
|
||||
|
||||
**Response:**
|
||||
```json
|
||||
{
|
||||
"projects": [
|
||||
{
|
||||
"id": "proj_123",
|
||||
"public_id": "proj_abc123",
|
||||
"name": "AI Research Project",
|
||||
"description": "Machine learning research initiative",
|
||||
"status": "active",
|
||||
"created_at": "2024-01-01T12:00:00Z",
|
||||
"updated_at": "2024-01-01T15:30:00Z",
|
||||
"created_by": "admin@example.com"
|
||||
}
|
||||
],
|
||||
"total": 1,
|
||||
"limit": 20,
|
||||
"offset": 0
|
||||
}
|
||||
```
|
||||
|
||||
**Example:**
|
||||
```bash
|
||||
curl -H "Authorization: Bearer <admin_token>" \
|
||||
"http://localhost:8080/v1/organization/projects?status=active"
|
||||
```
|
||||
|
||||
#### Create Project
|
||||
|
||||
**Endpoint**: `POST /v1/organization/projects`
|
||||
|
||||
Creates a new project within the organization.
|
||||
|
||||
**Request Body:**
|
||||
```json
|
||||
{
|
||||
"name": "New AI Project",
|
||||
"description": "Description of the new project",
|
||||
"settings": {
|
||||
"default_model": "jan-v1-4b",
|
||||
"max_conversations": 1000
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
**Parameters:**
|
||||
- `name` (string, required): Project name
|
||||
- `description` (string, optional): Project description
|
||||
- `settings` (object, optional): Project-specific settings
|
||||
|
||||
**Response:**
|
||||
```json
|
||||
{
|
||||
"id": "proj_789",
|
||||
"public_id": "proj_def456",
|
||||
"name": "New AI Project",
|
||||
"description": "Description of the new project",
|
||||
"status": "active",
|
||||
"created_at": "2024-01-01T12:00:00Z",
|
||||
"updated_at": "2024-01-01T12:00:00Z",
|
||||
"created_by": "admin@example.com",
|
||||
"settings": {
|
||||
"default_model": "jan-v1-4b",
|
||||
"max_conversations": 1000
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
**Example:**
|
||||
```bash
|
||||
curl -X POST http://localhost:8080/v1/organization/projects \
|
||||
-H "Authorization: Bearer <admin_token>" \
|
||||
-H "Content-Type: application/json" \
|
||||
-d '{
|
||||
"name": "New AI Project",
|
||||
"description": "Description of the new project",
|
||||
"settings": {
|
||||
"default_model": "jan-v1-4b"
|
||||
}
|
||||
}'
|
||||
```
|
||||
|
||||
#### Get Project
|
||||
|
||||
**Endpoint**: `GET /v1/organization/projects/{project_id}`
|
||||
|
||||
Retrieves details of a specific project.
|
||||
|
||||
**Path Parameters:**
|
||||
- `project_id` (string, required): The project ID
|
||||
|
||||
**Response:**
|
||||
```json
|
||||
{
|
||||
"id": "proj_123",
|
||||
"public_id": "proj_abc123",
|
||||
"name": "AI Research Project",
|
||||
"description": "Machine learning research initiative",
|
||||
"status": "active",
|
||||
"created_at": "2024-01-01T12:00:00Z",
|
||||
"updated_at": "2024-01-01T15:30:00Z",
|
||||
"created_by": "admin@example.com",
|
||||
"settings": {
|
||||
"default_model": "jan-v1-4b",
|
||||
"max_conversations": 1000
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
**Example:**
|
||||
```bash
|
||||
curl -H "Authorization: Bearer <admin_token>" \
|
||||
http://localhost:8080/v1/organization/projects/proj_123
|
||||
```
|
||||
|
||||
#### Update Project
|
||||
|
||||
**Endpoint**: `POST /v1/organization/projects/{project_id}`
|
||||
|
||||
Updates an existing project.
|
||||
|
||||
**Path Parameters:**
|
||||
- `project_id` (string, required): The project ID
|
||||
|
||||
**Request Body:**
|
||||
```json
|
||||
{
|
||||
"name": "Updated Project Name",
|
||||
"description": "Updated description",
|
||||
"settings": {
|
||||
"default_model": "jan-v1-7b",
|
||||
"max_conversations": 2000
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
**Response:**
|
||||
```json
|
||||
{
|
||||
"id": "proj_123",
|
||||
"public_id": "proj_abc123",
|
||||
"name": "Updated Project Name",
|
||||
"description": "Updated description",
|
||||
"status": "active",
|
||||
"created_at": "2024-01-01T12:00:00Z",
|
||||
"updated_at": "2024-01-01T16:00:00Z",
|
||||
"created_by": "admin@example.com",
|
||||
"settings": {
|
||||
"default_model": "jan-v1-7b",
|
||||
"max_conversations": 2000
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
**Example:**
|
||||
```bash
|
||||
curl -X POST http://localhost:8080/v1/organization/projects/proj_123 \
|
||||
-H "Authorization: Bearer <admin_token>" \
|
||||
-H "Content-Type: application/json" \
|
||||
-d '{
|
||||
"name": "Updated Project Name",
|
||||
"description": "Updated description"
|
||||
}'
|
||||
```
|
||||
|
||||
#### Archive Project
|
||||
|
||||
**Endpoint**: `POST /v1/organization/projects/{project_id}/archive`
|
||||
|
||||
Archives a project, making it read-only.
|
||||
|
||||
**Path Parameters:**
|
||||
- `project_id` (string, required): The project ID
|
||||
|
||||
**Response:**
|
||||
```json
|
||||
{
|
||||
"id": "proj_123",
|
||||
"public_id": "proj_abc123",
|
||||
"name": "AI Research Project",
|
||||
"description": "Machine learning research initiative",
|
||||
"status": "archived",
|
||||
"created_at": "2024-01-01T12:00:00Z",
|
||||
"updated_at": "2024-01-01T17:00:00Z",
|
||||
"created_by": "admin@example.com"
|
||||
}
|
||||
```
|
||||
|
||||
**Example:**
|
||||
```bash
|
||||
curl -X POST http://localhost:8080/v1/organization/projects/proj_123/archive \
|
||||
-H "Authorization: Bearer <admin_token>"
|
||||
```
|
||||
|
||||
### Project API Keys
|
||||
|
||||
#### List Project API Keys
|
||||
|
||||
**Endpoint**: `GET /v1/organization/projects/{project_public_id}/api_keys`
|
||||
|
||||
Retrieves API keys for a specific project.
|
||||
|
||||
**Path Parameters:**
|
||||
- `project_public_id` (string, required): The project public ID
|
||||
|
||||
**Response:**
|
||||
```json
|
||||
{
|
||||
"api_keys": [
|
||||
{
|
||||
"id": "pk_123",
|
||||
"name": "Production API Key",
|
||||
"created_at": "2024-01-01T12:00:00Z",
|
||||
"last_used": "2024-01-01T15:30:00Z",
|
||||
"is_active": true
|
||||
}
|
||||
],
|
||||
"total": 1
|
||||
}
|
||||
```
|
||||
|
||||
**Example:**
|
||||
```bash
|
||||
curl -H "Authorization: Bearer <admin_token>" \
|
||||
http://localhost:8080/v1/organization/projects/proj_abc123/api_keys
|
||||
```
|
||||
|
||||
#### Create Project API Key
|
||||
|
||||
**Endpoint**: `POST /v1/organization/projects/{project_public_id}/api_keys`
|
||||
|
||||
Creates a new API key for a specific project.
|
||||
|
||||
**Path Parameters:**
|
||||
- `project_public_id` (string, required): The project public ID
|
||||
|
||||
**Request Body:**
|
||||
```json
|
||||
{
|
||||
"name": "Development API Key",
|
||||
"expires_at": "2024-12-31T23:59:59Z"
|
||||
}
|
||||
```
|
||||
|
||||
**Response:**
|
||||
```json
|
||||
{
|
||||
"id": "pk_456",
|
||||
"name": "Development API Key",
|
||||
"key": "jan_pk_1234567890abcdef",
|
||||
"created_at": "2024-01-01T12:00:00Z",
|
||||
"expires_at": "2024-12-31T23:59:59Z",
|
||||
"is_active": true
|
||||
}
|
||||
```
|
||||
|
||||
**Example:**
|
||||
```bash
|
||||
curl -X POST http://localhost:8080/v1/organization/projects/proj_abc123/api_keys \
|
||||
-H "Authorization: Bearer <admin_token>" \
|
||||
-H "Content-Type: application/json" \
|
||||
-d '{
|
||||
"name": "Development API Key",
|
||||
"expires_at": "2024-12-31T23:59:59Z"
|
||||
}'
|
||||
```
|
||||
|
||||
## Permissions and Roles
|
||||
|
||||
### Organization Roles
|
||||
|
||||
- **Admin**: Full access to all organization resources
|
||||
- **Member**: Access to assigned projects and resources
|
||||
- **Viewer**: Read-only access to assigned projects
|
||||
|
||||
### API Key Permissions
|
||||
|
||||
- **admin**: Full administrative access
|
||||
- **read**: Read-only access to resources
|
||||
- **write**: Read and write access to resources
|
||||
|
||||
## Error Responses
|
||||
|
||||
### Common Error Codes
|
||||
|
||||
| Status Code | Description |
|
||||
|-------------|-------------|
|
||||
| `400` | Bad Request - Invalid request format or parameters |
|
||||
| `401` | Unauthorized - Invalid or missing authentication |
|
||||
| `403` | Forbidden - Insufficient permissions |
|
||||
| `404` | Not Found - Resource not found |
|
||||
| `409` | Conflict - Resource already exists |
|
||||
| `429` | Too Many Requests - Rate limit exceeded |
|
||||
| `500` | Internal Server Error - Server error |
|
||||
|
||||
### Error Response Format
|
||||
|
||||
```json
|
||||
{
|
||||
"error": {
|
||||
"message": "Insufficient permissions",
|
||||
"type": "forbidden_error",
|
||||
"code": "insufficient_permissions"
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
## Best Practices
|
||||
|
||||
### Security
|
||||
|
||||
1. **Rotate API Keys**: Regularly rotate API keys for security
|
||||
2. **Least Privilege**: Grant minimum required permissions
|
||||
3. **Monitor Usage**: Track API key usage and access patterns
|
||||
4. **Secure Storage**: Store API keys securely and never expose them
|
||||
|
||||
### Organization Management
|
||||
|
||||
1. **Clear Roles**: Define clear role hierarchies and permissions
|
||||
2. **Regular Audits**: Periodically review user access and permissions
|
||||
3. **Project Organization**: Organize projects logically by team or function
|
||||
4. **Documentation**: Maintain clear documentation of organization structure
|
||||
|
||||
## Rate Limiting
|
||||
|
||||
Organization endpoints have the following rate limits:
|
||||
- **Admin operations**: 100 requests per minute
|
||||
- **Project operations**: 200 requests per minute
|
||||
- **API key operations**: 50 requests per minute
|
||||
- **Invite operations**: 20 requests per minute
|
||||
|
||||
Rate limit headers are included in responses:
|
||||
```
|
||||
X-RateLimit-Limit: 100
|
||||
X-RateLimit-Remaining: 99
|
||||
X-RateLimit-Reset: 1609459200
|
||||
```
|
||||
@ -1,208 +0,0 @@
|
||||
---
|
||||
title: Authentication
|
||||
description: User authentication and authorization endpoints for Jan Server.
|
||||
---
|
||||
|
||||
## Overview
|
||||
|
||||
The Authentication API provides endpoints for user authentication, authorization, and session management. Jan Server supports multiple authentication methods including Google OAuth2, JWT tokens, and guest access.
|
||||
|
||||
## Endpoints
|
||||
|
||||
### Google OAuth2 Callback
|
||||
|
||||
**Endpoint**: `POST /v1/auth/google/callback`
|
||||
|
||||
Handles the callback from the Google OAuth2 provider to exchange the authorization code for a token, verify the user, and issue access and refresh tokens.
|
||||
|
||||
**Request Body:**
|
||||
```json
|
||||
{
|
||||
"code": "string",
|
||||
"state": "string"
|
||||
}
|
||||
```
|
||||
|
||||
**Response:**
|
||||
```json
|
||||
{
|
||||
"access_token": "string",
|
||||
"refresh_token": "string",
|
||||
"expires_in": 3600,
|
||||
"token_type": "Bearer"
|
||||
}
|
||||
```
|
||||
|
||||
**Example:**
|
||||
```bash
|
||||
curl -X POST http://localhost:8080/v1/auth/google/callback \
|
||||
-H "Content-Type: application/json" \
|
||||
-d '{
|
||||
"code": "4/0AX4XfWh...",
|
||||
"state": "random_state_string"
|
||||
}'
|
||||
```
|
||||
|
||||
### Google OAuth2 Login
|
||||
|
||||
**Endpoint**: `GET /v1/auth/google/login`
|
||||
|
||||
Initiates Google OAuth2 authentication flow by redirecting to Google's authorization server.
|
||||
|
||||
**Response:**
|
||||
```json
|
||||
{
|
||||
"url": "https://accounts.google.com/oauth/authorize?..."
|
||||
}
|
||||
```
|
||||
|
||||
**Example:**
|
||||
```bash
|
||||
curl http://localhost:8080/v1/auth/google/login
|
||||
```
|
||||
|
||||
### Guest Login
|
||||
|
||||
**Endpoint**: `POST /v1/auth/guest-login`
|
||||
|
||||
Creates a guest session with limited access for users who don't want to authenticate with Google.
|
||||
|
||||
**Response:**
|
||||
```json
|
||||
{
|
||||
"access_token": "string",
|
||||
"refresh_token": "string",
|
||||
"expires_in": 3600,
|
||||
"token_type": "Bearer"
|
||||
}
|
||||
```
|
||||
|
||||
**Example:**
|
||||
```bash
|
||||
curl -X POST http://localhost:8080/v1/auth/guest-login \
|
||||
-H "Content-Type: application/json"
|
||||
```
|
||||
|
||||
### Logout
|
||||
|
||||
**Endpoint**: `GET /v1/auth/logout`
|
||||
|
||||
Invalidates the current user session and refresh token.
|
||||
|
||||
**Headers:**
|
||||
- `Authorization: Bearer <refresh_token>`
|
||||
|
||||
**Response:**
|
||||
```
|
||||
200 OK
|
||||
```
|
||||
|
||||
**Example:**
|
||||
```bash
|
||||
curl -H "Authorization: Bearer <refresh_token>" \
|
||||
http://localhost:8080/v1/auth/logout
|
||||
```
|
||||
|
||||
### Get User Profile
|
||||
|
||||
**Endpoint**: `GET /v1/auth/me`
|
||||
|
||||
Retrieves the current user's profile information.
|
||||
|
||||
**Headers:**
|
||||
- `Authorization: Bearer <access_token>`
|
||||
|
||||
**Response:**
|
||||
```json
|
||||
{
|
||||
"id": "string",
|
||||
"email": "string",
|
||||
"name": "string",
|
||||
"picture": "string",
|
||||
"is_guest": false,
|
||||
"created_at": "2024-01-01T00:00:00Z",
|
||||
"updated_at": "2024-01-01T00:00:00Z"
|
||||
}
|
||||
```
|
||||
|
||||
**Example:**
|
||||
```bash
|
||||
curl -H "Authorization: Bearer <access_token>" \
|
||||
http://localhost:8080/v1/auth/me
|
||||
```
|
||||
|
||||
### Refresh Access Token
|
||||
|
||||
**Endpoint**: `GET /v1/auth/refresh-token`
|
||||
|
||||
Refreshes an expired access token using a valid refresh token.
|
||||
|
||||
**Headers:**
|
||||
- `Authorization: Bearer <refresh_token>`
|
||||
|
||||
**Response:**
|
||||
```json
|
||||
{
|
||||
"access_token": "string",
|
||||
"refresh_token": "string",
|
||||
"expires_in": 3600,
|
||||
"token_type": "Bearer"
|
||||
}
|
||||
```
|
||||
|
||||
**Example:**
|
||||
```bash
|
||||
curl -H "Authorization: Bearer <refresh_token>" \
|
||||
http://localhost:8080/v1/auth/refresh-token
|
||||
```
|
||||
|
||||
## Authentication Methods
|
||||
|
||||
### JWT Token Authentication
|
||||
|
||||
Include JWT token in the Authorization header:
|
||||
|
||||
```bash
|
||||
curl -H "Authorization: Bearer <jwt_token>" \
|
||||
http://localhost:8080/v1/protected-endpoint
|
||||
```
|
||||
|
||||
### API Key Authentication
|
||||
|
||||
Include API key in the Authorization header:
|
||||
|
||||
```bash
|
||||
curl -H "Authorization: Bearer <api_key>" \
|
||||
http://localhost:8080/v1/protected-endpoint
|
||||
```
|
||||
|
||||
## Error Responses
|
||||
|
||||
### Common Error Codes
|
||||
|
||||
| Status Code | Description |
|
||||
|-------------|-------------|
|
||||
| `400` | Bad Request - Invalid request format or parameters |
|
||||
| `401` | Unauthorized - Invalid or missing authentication |
|
||||
| `403` | Forbidden - Insufficient permissions |
|
||||
| `500` | Internal Server Error - Server error |
|
||||
|
||||
### Error Response Format
|
||||
|
||||
```json
|
||||
{
|
||||
"error": {
|
||||
"message": "Invalid request format",
|
||||
"type": "invalid_request_error",
|
||||
"code": "invalid_json"
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
## Security Considerations
|
||||
|
||||
- **Token Expiration**: Access tokens expire after 1 hour by default
|
||||
- **Refresh Tokens**: Refresh tokens are used to obtain new access tokens
|
||||
- **Guest Access**: Guest sessions have limited permissions and shorter expiration times
|
||||
- **HTTPS**: Always use HTTPS in production environments
|
||||
- **Token Storage**: Store tokens securely and never expose them in client-side code
|
||||
@ -1,293 +0,0 @@
|
||||
---
|
||||
title: Chat Conversations
|
||||
description: Conversation-aware chat endpoints for context-aware AI interactions.
|
||||
---
|
||||
|
||||
## Overview
|
||||
|
||||
The Chat Conversations API provides conversation-aware chat completion endpoints that maintain context across multiple interactions. These endpoints are designed for applications that need to preserve conversation history and provide context-aware responses.
|
||||
|
||||
## Endpoints
|
||||
|
||||
### Create Conversation-Aware Chat Completion
|
||||
|
||||
**Endpoint**: `POST /v1/conv/chat/completions`
|
||||
|
||||
Creates a chat completion that is aware of the conversation context and history.
|
||||
|
||||
**Request Body:**
|
||||
```json
|
||||
{
|
||||
"model": "string",
|
||||
"messages": [
|
||||
{
|
||||
"role": "user",
|
||||
"content": "What did we discuss earlier about machine learning?"
|
||||
}
|
||||
],
|
||||
"conversation_id": "conv_123",
|
||||
"max_tokens": 200,
|
||||
"temperature": 0.7,
|
||||
"stream": false
|
||||
}
|
||||
```
|
||||
|
||||
**Parameters:**
|
||||
- `model` (string, required): Model identifier (e.g., "jan-v1-4b")
|
||||
- `messages` (array, required): Array of message objects with role and content
|
||||
- `conversation_id` (string, optional): ID of the conversation for context
|
||||
- `max_tokens` (integer, optional): Maximum number of tokens to generate
|
||||
- `temperature` (float, optional): Sampling temperature (0.0 to 2.0)
|
||||
- `stream` (boolean, optional): Whether to stream the response
|
||||
|
||||
**Response:**
|
||||
```json
|
||||
{
|
||||
"id": "chatcmpl-123",
|
||||
"object": "chat.completion",
|
||||
"created": 1677652288,
|
||||
"model": "jan-v1-4b",
|
||||
"conversation_id": "conv_123",
|
||||
"choices": [
|
||||
{
|
||||
"index": 0,
|
||||
"message": {
|
||||
"role": "assistant",
|
||||
"content": "Earlier we discussed the basics of supervised learning, including how algorithms learn from labeled training data to make predictions on new, unseen data."
|
||||
},
|
||||
"finish_reason": "stop"
|
||||
}
|
||||
],
|
||||
"usage": {
|
||||
"prompt_tokens": 15,
|
||||
"completion_tokens": 28,
|
||||
"total_tokens": 43
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
**Example:**
|
||||
```bash
|
||||
curl -X POST http://localhost:8080/v1/conv/chat/completions \
|
||||
-H "Content-Type: application/json" \
|
||||
-H "Authorization: Bearer <token>" \
|
||||
-d '{
|
||||
"model": "jan-v1-4b",
|
||||
"messages": [
|
||||
{"role": "user", "content": "What did we discuss earlier about machine learning?"}
|
||||
],
|
||||
"conversation_id": "conv_123",
|
||||
"max_tokens": 200,
|
||||
"temperature": 0.7
|
||||
}'
|
||||
```
|
||||
|
||||
### MCP Streamable Endpoint for Conversations
|
||||
|
||||
**Endpoint**: `POST /v1/conv/mcp`
|
||||
|
||||
Model Context Protocol streamable endpoint specifically designed for conversation-aware chat with external tool integration.
|
||||
|
||||
**Request Body:**
|
||||
```json
|
||||
{
|
||||
"model": "string",
|
||||
"messages": [
|
||||
{
|
||||
"role": "user",
|
||||
"content": "Can you help me analyze the data we collected yesterday?"
|
||||
}
|
||||
],
|
||||
"conversation_id": "conv_123",
|
||||
"tools": [
|
||||
{
|
||||
"type": "function",
|
||||
"function": {
|
||||
"name": "analyze_data",
|
||||
"description": "Analyze collected data from previous conversation",
|
||||
"parameters": {
|
||||
"type": "object",
|
||||
"properties": {
|
||||
"data_type": {
|
||||
"type": "string",
|
||||
"description": "Type of data to analyze"
|
||||
}
|
||||
},
|
||||
"required": ["data_type"]
|
||||
}
|
||||
}
|
||||
}
|
||||
],
|
||||
"stream": true
|
||||
}
|
||||
```
|
||||
|
||||
**Response (Streaming):**
|
||||
```
|
||||
data: {"id":"chatcmpl-123","object":"chat.completion.chunk","created":1677652288,"model":"jan-v1-4b","conversation_id":"conv_123","choices":[{"index":0,"delta":{"role":"assistant","content":""},"finish_reason":null}]}
|
||||
|
||||
data: {"id":"chatcmpl-123","object":"chat.completion.chunk","created":1677652288,"model":"jan-v1-4b","conversation_id":"conv_123","choices":[{"index":0,"delta":{"content":"I'll"},"finish_reason":null}]}
|
||||
|
||||
data: {"id":"chatcmpl-123","object":"chat.completion.chunk","created":1677652288,"model":"jan-v1-4b","conversation_id":"conv_123","choices":[{"index":0,"delta":{"content":" analyze"},"finish_reason":null}]}
|
||||
|
||||
data: [DONE]
|
||||
```
|
||||
|
||||
**Example:**
|
||||
```bash
|
||||
curl -X POST http://localhost:8080/v1/conv/mcp \
|
||||
-H "Content-Type: application/json" \
|
||||
-H "Authorization: Bearer <token>" \
|
||||
-d '{
|
||||
"model": "jan-v1-4b",
|
||||
"messages": [
|
||||
{"role": "user", "content": "Can you help me analyze the data we collected yesterday?"}
|
||||
],
|
||||
"conversation_id": "conv_123",
|
||||
"tools": [
|
||||
{
|
||||
"type": "function",
|
||||
"function": {
|
||||
"name": "analyze_data",
|
||||
"description": "Analyze collected data from previous conversation"
|
||||
}
|
||||
}
|
||||
],
|
||||
"stream": true
|
||||
}' \
|
||||
--no-buffer
|
||||
```
|
||||
|
||||
### List Available Models for Conversations
|
||||
|
||||
**Endpoint**: `GET /v1/conv/models`
|
||||
|
||||
Retrieves a list of available models specifically optimized for conversation-aware chat completions.
|
||||
|
||||
**Response:**
|
||||
```json
|
||||
{
|
||||
"object": "list",
|
||||
"data": [
|
||||
{
|
||||
"id": "jan-v1-4b-conv",
|
||||
"object": "model",
|
||||
"created": 1677652288,
|
||||
"owned_by": "jan",
|
||||
"capabilities": ["conversation_aware", "context_retention"]
|
||||
},
|
||||
{
|
||||
"id": "jan-v1-7b-conv",
|
||||
"object": "model",
|
||||
"created": 1677652288,
|
||||
"owned_by": "jan",
|
||||
"capabilities": ["conversation_aware", "context_retention", "long_context"]
|
||||
}
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
**Example:**
|
||||
```bash
|
||||
curl http://localhost:8080/v1/conv/models
|
||||
```
|
||||
|
||||
## Conversation Context
|
||||
|
||||
### Context Retention
|
||||
|
||||
Conversation-aware endpoints automatically maintain context by:
|
||||
- Storing conversation history in the database
|
||||
- Retrieving relevant context for each request
|
||||
- Providing context-aware responses based on previous interactions
|
||||
|
||||
### Conversation ID
|
||||
|
||||
The `conversation_id` parameter links requests to a specific conversation:
|
||||
- If provided, the system retrieves conversation history
|
||||
- If omitted, a new conversation context is created
|
||||
- Context is maintained across multiple API calls
|
||||
|
||||
### Context Window
|
||||
|
||||
The system maintains a sliding window of conversation history:
|
||||
- Recent messages are prioritized
|
||||
- Older context is summarized when needed
|
||||
- Maximum context length varies by model
|
||||
|
||||
## Advanced Features
|
||||
|
||||
### Context Summarization
|
||||
|
||||
For long conversations, the system automatically:
|
||||
- Summarizes older message history
|
||||
- Preserves key information and decisions
|
||||
- Maintains conversation flow continuity
|
||||
|
||||
### Multi-Turn Interactions
|
||||
|
||||
Support for complex multi-turn conversations:
|
||||
- Reference previous topics and decisions
|
||||
- Maintain user preferences and settings
|
||||
- Provide consistent personality and tone
|
||||
|
||||
### Context-Aware Tool Usage
|
||||
|
||||
Tools can access conversation context:
|
||||
- Reference previous data and results
|
||||
- Build upon previous analysis
|
||||
- Maintain state across interactions
|
||||
|
||||
## Error Responses
|
||||
|
||||
### Common Error Codes
|
||||
|
||||
| Status Code | Description |
|
||||
|-------------|-------------|
|
||||
| `400` | Bad Request - Invalid request format or conversation ID |
|
||||
| `401` | Unauthorized - Invalid or missing authentication |
|
||||
| `404` | Not Found - Conversation not found |
|
||||
| `429` | Too Many Requests - Rate limit exceeded |
|
||||
| `500` | Internal Server Error - Server error |
|
||||
|
||||
### Error Response Format
|
||||
|
||||
```json
|
||||
{
|
||||
"error": {
|
||||
"message": "Conversation not found",
|
||||
"type": "not_found_error",
|
||||
"code": "conversation_not_found"
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
## Best Practices
|
||||
|
||||
### Conversation Management
|
||||
|
||||
1. **Use Consistent Conversation IDs**: Maintain the same ID across related requests
|
||||
2. **Provide Context**: Include relevant context in your messages
|
||||
3. **Handle Long Conversations**: Be aware of context window limitations
|
||||
4. **Clean Up**: Delete old conversations when no longer needed
|
||||
|
||||
### Performance Optimization
|
||||
|
||||
1. **Batch Requests**: Group related requests when possible
|
||||
2. **Stream Responses**: Use streaming for better user experience
|
||||
3. **Cache Context**: Store conversation context client-side when appropriate
|
||||
4. **Monitor Usage**: Track token usage and conversation length
|
||||
|
||||
## Rate Limiting
|
||||
|
||||
Conversation-aware endpoints have the following rate limits:
|
||||
- **Authenticated users**: 30 requests per minute
|
||||
- **API keys**: 500 requests per hour
|
||||
- **Guest users**: 5 requests per minute
|
||||
|
||||
Rate limit headers are included in responses:
|
||||
```
|
||||
X-RateLimit-Limit: 30
|
||||
X-RateLimit-Remaining: 29
|
||||
X-RateLimit-Reset: 1609459200
|
||||
```
|
||||
@ -1,320 +0,0 @@
|
||||
---
|
||||
title: Completions API
|
||||
description: Core chat completion endpoints for AI interactions with OpenAI compatibility.
|
||||
---
|
||||
|
||||
## Overview
|
||||
|
||||
The Chat API provides OpenAI-compatible endpoints for conversational AI interactions, including chat completions, model information, and Model Context Protocol (MCP) support.
|
||||
|
||||
## Endpoints
|
||||
|
||||
### Create Chat Completion
|
||||
|
||||
**Endpoint**: `POST /v1/chat/completions`
|
||||
|
||||
Creates a chat completion using the specified model and conversation history.
|
||||
|
||||
**Request Body:**
|
||||
```json
|
||||
{
|
||||
"model": "string",
|
||||
"messages": [
|
||||
{
|
||||
"role": "user",
|
||||
"content": "Hello, how are you?"
|
||||
}
|
||||
],
|
||||
"max_tokens": 100,
|
||||
"temperature": 0.7,
|
||||
"stream": false
|
||||
}
|
||||
```
|
||||
|
||||
**Parameters:**
|
||||
- `model` (string, required): Model identifier (e.g., "jan-v1-4b")
|
||||
- `messages` (array, required): Array of message objects with role and content
|
||||
- `max_tokens` (integer, optional): Maximum number of tokens to generate
|
||||
- `temperature` (float, optional): Sampling temperature (0.0 to 2.0)
|
||||
- `stream` (boolean, optional): Whether to stream the response
|
||||
|
||||
**Response:**
|
||||
```json
|
||||
{
|
||||
"id": "chatcmpl-123",
|
||||
"object": "chat.completion",
|
||||
"created": 1677652288,
|
||||
"model": "jan-v1-4b",
|
||||
"choices": [
|
||||
{
|
||||
"index": 0,
|
||||
"message": {
|
||||
"role": "assistant",
|
||||
"content": "Hello! I'm doing well, thank you for asking."
|
||||
},
|
||||
"finish_reason": "stop"
|
||||
}
|
||||
],
|
||||
"usage": {
|
||||
"prompt_tokens": 9,
|
||||
"completion_tokens": 12,
|
||||
"total_tokens": 21
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
**Example:**
|
||||
```bash
|
||||
curl -X POST http://localhost:8080/v1/chat/completions \
|
||||
-H "Content-Type: application/json" \
|
||||
-H "Authorization: Bearer <token>" \
|
||||
-d '{
|
||||
"model": "jan-v1-4b",
|
||||
"messages": [
|
||||
{"role": "user", "content": "Hello, how are you?"}
|
||||
],
|
||||
"max_tokens": 100,
|
||||
"temperature": 0.7
|
||||
}'
|
||||
```
|
||||
|
||||
### Streaming Chat Completion
|
||||
|
||||
**Endpoint**: `POST /v1/chat/completions`
|
||||
|
||||
Same endpoint as above, but with `stream: true` for real-time responses.
|
||||
|
||||
**Request Body:**
|
||||
```json
|
||||
{
|
||||
"model": "jan-v1-4b",
|
||||
"messages": [
|
||||
{"role": "user", "content": "Tell me a story"}
|
||||
],
|
||||
"stream": true
|
||||
}
|
||||
```
|
||||
|
||||
**Response (Streaming):**
|
||||
```
|
||||
data: {"id":"chatcmpl-123","object":"chat.completion.chunk","created":1677652288,"model":"jan-v1-4b","choices":[{"index":0,"delta":{"role":"assistant","content":""},"finish_reason":null}]}
|
||||
|
||||
data: {"id":"chatcmpl-123","object":"chat.completion.chunk","created":1677652288,"model":"jan-v1-4b","choices":[{"index":0,"delta":{"content":"Once"},"finish_reason":null}]}
|
||||
|
||||
data: {"id":"chatcmpl-123","object":"chat.completion.chunk","created":1677652288,"model":"jan-v1-4b","choices":[{"index":0,"delta":{"content":" upon"},"finish_reason":null}]}
|
||||
|
||||
data: [DONE]
|
||||
```
|
||||
|
||||
**Example:**
|
||||
```bash
|
||||
curl -X POST http://localhost:8080/v1/chat/completions \
|
||||
-H "Content-Type: application/json" \
|
||||
-H "Authorization: Bearer <token>" \
|
||||
-d '{
|
||||
"model": "jan-v1-4b",
|
||||
"messages": [{"role": "user", "content": "Tell me a story"}],
|
||||
"stream": true
|
||||
}' \
|
||||
--no-buffer
|
||||
```
|
||||
|
||||
### MCP Streamable Endpoint
|
||||
|
||||
**Endpoint**: `POST /v1/mcp`
|
||||
|
||||
Model Context Protocol streamable endpoint for external tool integration.
|
||||
|
||||
**Request Body:**
|
||||
```json
|
||||
{
|
||||
"model": "string",
|
||||
"messages": [
|
||||
{
|
||||
"role": "user",
|
||||
"content": "What's the weather like today?"
|
||||
}
|
||||
],
|
||||
"tools": [
|
||||
{
|
||||
"type": "function",
|
||||
"function": {
|
||||
"name": "get_weather",
|
||||
"description": "Get current weather information",
|
||||
"parameters": {
|
||||
"type": "object",
|
||||
"properties": {
|
||||
"location": {
|
||||
"type": "string",
|
||||
"description": "The city and state"
|
||||
}
|
||||
},
|
||||
"required": ["location"]
|
||||
}
|
||||
}
|
||||
}
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
**Response:**
|
||||
```json
|
||||
{
|
||||
"id": "chatcmpl-123",
|
||||
"object": "chat.completion",
|
||||
"created": 1677652288,
|
||||
"model": "jan-v1-4b",
|
||||
"choices": [
|
||||
{
|
||||
"index": 0,
|
||||
"message": {
|
||||
"role": "assistant",
|
||||
"content": "I'll check the weather for you.",
|
||||
"tool_calls": [
|
||||
{
|
||||
"id": "call_123",
|
||||
"type": "function",
|
||||
"function": {
|
||||
"name": "get_weather",
|
||||
"arguments": "{\"location\": \"New York, NY\"}"
|
||||
}
|
||||
}
|
||||
]
|
||||
},
|
||||
"finish_reason": "tool_calls"
|
||||
}
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
**Example:**
|
||||
```bash
|
||||
curl -X POST http://localhost:8080/v1/mcp \
|
||||
-H "Content-Type: application/json" \
|
||||
-H "Authorization: Bearer <token>" \
|
||||
-d '{
|
||||
"model": "jan-v1-4b",
|
||||
"messages": [
|
||||
{"role": "user", "content": "What'\''s the weather like today?"}
|
||||
],
|
||||
"tools": [
|
||||
{
|
||||
"type": "function",
|
||||
"function": {
|
||||
"name": "get_weather",
|
||||
"description": "Get current weather information"
|
||||
}
|
||||
}
|
||||
]
|
||||
}'
|
||||
```
|
||||
|
||||
### List Available Models
|
||||
|
||||
**Endpoint**: `GET /v1/models`
|
||||
|
||||
Retrieves a list of available models for chat completions.
|
||||
|
||||
**Response:**
|
||||
```json
|
||||
{
|
||||
"object": "list",
|
||||
"data": [
|
||||
{
|
||||
"id": "jan-v1-4b",
|
||||
"object": "model",
|
||||
"created": 1677652288,
|
||||
"owned_by": "jan"
|
||||
},
|
||||
{
|
||||
"id": "jan-v1-7b",
|
||||
"object": "model",
|
||||
"created": 1677652288,
|
||||
"owned_by": "jan"
|
||||
}
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
**Example:**
|
||||
```bash
|
||||
curl http://localhost:8080/v1/models
|
||||
```
|
||||
|
||||
## Message Roles
|
||||
|
||||
### Supported Roles
|
||||
|
||||
- `user`: Messages from the user/end-user
|
||||
- `assistant`: Messages from the AI assistant
|
||||
- `system`: System-level instructions (optional)
|
||||
|
||||
### Message Format
|
||||
|
||||
```json
|
||||
{
|
||||
"role": "user|assistant|system",
|
||||
"content": "The message content"
|
||||
}
|
||||
```
|
||||
|
||||
## Parameters
|
||||
|
||||
### Temperature
|
||||
|
||||
Controls the randomness of the response:
|
||||
- `0.0`: Deterministic, always picks the most likely token
|
||||
- `0.7`: Balanced creativity and coherence (recommended)
|
||||
- `1.0`: More creative responses
|
||||
- `2.0`: Maximum creativity
|
||||
|
||||
### Max Tokens
|
||||
|
||||
Maximum number of tokens to generate in the response:
|
||||
- Minimum: 1
|
||||
- Maximum: 4096 (varies by model)
|
||||
- Recommended: 100-500 for most use cases
|
||||
|
||||
### Stream
|
||||
|
||||
When `true`, returns a stream of Server-Sent Events (SSE) instead of a single response:
|
||||
- Useful for real-time applications
|
||||
- Reduces perceived latency
|
||||
- Requires handling of streaming responses
|
||||
|
||||
## Error Responses
|
||||
|
||||
### Common Error Codes
|
||||
|
||||
| Status Code | Description |
|
||||
|-------------|-------------|
|
||||
| `400` | Bad Request - Invalid request format or parameters |
|
||||
| `401` | Unauthorized - Invalid or missing authentication |
|
||||
| `429` | Too Many Requests - Rate limit exceeded |
|
||||
| `500` | Internal Server Error - Server error |
|
||||
|
||||
### Error Response Format
|
||||
|
||||
```json
|
||||
{
|
||||
"error": {
|
||||
"message": "Invalid request format",
|
||||
"type": "invalid_request_error",
|
||||
"code": "invalid_json"
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
## Rate Limiting
|
||||
|
||||
Chat completion endpoints have the following rate limits:
|
||||
- **Authenticated users**: 60 requests per minute
|
||||
- **API keys**: 1000 requests per hour
|
||||
- **Guest users**: 10 requests per minute
|
||||
|
||||
Rate limit headers are included in responses:
|
||||
```
|
||||
X-RateLimit-Limit: 60
|
||||
X-RateLimit-Remaining: 59
|
||||
X-RateLimit-Reset: 1609459200
|
||||
```
|
||||
@ -1,475 +0,0 @@
|
||||
---
|
||||
title: Conversations API
|
||||
description: Conversation management and persistence endpoints for storing and retrieving chat history.
|
||||
---
|
||||
|
||||
## Overview
|
||||
|
||||
The Conversations API provides comprehensive endpoints for managing conversation data, including creating, reading, updating, and deleting conversations and their associated items (messages). This API is essential for applications that need to persist chat history and manage conversation state.
|
||||
|
||||
## Endpoints
|
||||
|
||||
### List Conversations
|
||||
|
||||
**Endpoint**: `GET /v1/conversations`
|
||||
|
||||
Retrieves a paginated list of conversations for the authenticated user.
|
||||
|
||||
**Query Parameters:**
|
||||
- `limit` (integer, optional): Number of conversations to return (1-100, default: 20)
|
||||
- `offset` (integer, optional): Number of conversations to skip (default: 0)
|
||||
- `order` (string, optional): Sort order - "asc" or "desc" (default: "desc")
|
||||
|
||||
**Response:**
|
||||
```json
|
||||
{
|
||||
"conversations": [
|
||||
{
|
||||
"id": "conv_123",
|
||||
"title": "Machine Learning Discussion",
|
||||
"model": "jan-v1-4b",
|
||||
"created_at": "2024-01-01T12:00:00Z",
|
||||
"updated_at": "2024-01-01T13:30:00Z",
|
||||
"item_count": 15,
|
||||
"user_id": "user_456"
|
||||
}
|
||||
],
|
||||
"total": 1,
|
||||
"limit": 20,
|
||||
"offset": 0
|
||||
}
|
||||
```
|
||||
|
||||
**Example:**
|
||||
```bash
|
||||
curl -H "Authorization: Bearer <token>" \
|
||||
"http://localhost:8080/v1/conversations?limit=10&offset=0"
|
||||
```
|
||||
|
||||
### Create Conversation
|
||||
|
||||
**Endpoint**: `POST /v1/conversations`
|
||||
|
||||
Creates a new conversation with optional initial data.
|
||||
|
||||
**Request Body:**
|
||||
```json
|
||||
{
|
||||
"title": "New Conversation",
|
||||
"model": "jan-v1-4b",
|
||||
"metadata": {
|
||||
"category": "technical",
|
||||
"priority": "high"
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
**Parameters:**
|
||||
- `title` (string, optional): Conversation title
|
||||
- `model` (string, optional): Default model for the conversation
|
||||
- `metadata` (object, optional): Additional metadata
|
||||
|
||||
**Response:**
|
||||
```json
|
||||
{
|
||||
"id": "conv_789",
|
||||
"title": "New Conversation",
|
||||
"model": "jan-v1-4b",
|
||||
"created_at": "2024-01-01T14:00:00Z",
|
||||
"updated_at": "2024-01-01T14:00:00Z",
|
||||
"item_count": 0,
|
||||
"user_id": "user_456",
|
||||
"metadata": {
|
||||
"category": "technical",
|
||||
"priority": "high"
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
**Example:**
|
||||
```bash
|
||||
curl -X POST http://localhost:8080/v1/conversations \
|
||||
-H "Authorization: Bearer <token>" \
|
||||
-H "Content-Type: application/json" \
|
||||
-d '{
|
||||
"title": "New Conversation",
|
||||
"model": "jan-v1-4b",
|
||||
"metadata": {
|
||||
"category": "technical"
|
||||
}
|
||||
}'
|
||||
```
|
||||
|
||||
### Get Conversation
|
||||
|
||||
**Endpoint**: `GET /v1/conversations/{conversation_id}`
|
||||
|
||||
Retrieves a specific conversation by ID.
|
||||
|
||||
**Path Parameters:**
|
||||
- `conversation_id` (string, required): The conversation ID
|
||||
|
||||
**Response:**
|
||||
```json
|
||||
{
|
||||
"id": "conv_123",
|
||||
"title": "Machine Learning Discussion",
|
||||
"model": "jan-v1-4b",
|
||||
"created_at": "2024-01-01T12:00:00Z",
|
||||
"updated_at": "2024-01-01T13:30:00Z",
|
||||
"item_count": 15,
|
||||
"user_id": "user_456",
|
||||
"metadata": {
|
||||
"category": "technical",
|
||||
"priority": "high"
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
**Example:**
|
||||
```bash
|
||||
curl -H "Authorization: Bearer <token>" \
|
||||
http://localhost:8080/v1/conversations/conv_123
|
||||
```
|
||||
|
||||
### Update Conversation
|
||||
|
||||
**Endpoint**: `PATCH /v1/conversations/{conversation_id}`
|
||||
|
||||
Updates an existing conversation's metadata.
|
||||
|
||||
**Path Parameters:**
|
||||
- `conversation_id` (string, required): The conversation ID
|
||||
|
||||
**Request Body:**
|
||||
```json
|
||||
{
|
||||
"title": "Updated Conversation Title",
|
||||
"metadata": {
|
||||
"category": "research",
|
||||
"priority": "medium",
|
||||
"tags": ["ai", "ml"]
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
**Response:**
|
||||
```json
|
||||
{
|
||||
"id": "conv_123",
|
||||
"title": "Updated Conversation Title",
|
||||
"model": "jan-v1-4b",
|
||||
"created_at": "2024-01-01T12:00:00Z",
|
||||
"updated_at": "2024-01-01T15:00:00Z",
|
||||
"item_count": 15,
|
||||
"user_id": "user_456",
|
||||
"metadata": {
|
||||
"category": "research",
|
||||
"priority": "medium",
|
||||
"tags": ["ai", "ml"]
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
**Example:**
|
||||
```bash
|
||||
curl -X PATCH http://localhost:8080/v1/conversations/conv_123 \
|
||||
-H "Authorization: Bearer <token>" \
|
||||
-H "Content-Type: application/json" \
|
||||
-d '{
|
||||
"title": "Updated Conversation Title",
|
||||
"metadata": {
|
||||
"category": "research",
|
||||
"tags": ["ai", "ml"]
|
||||
}
|
||||
}'
|
||||
```
|
||||
|
||||
### Delete Conversation
|
||||
|
||||
**Endpoint**: `DELETE /v1/conversations/{conversation_id}`
|
||||
|
||||
Permanently deletes a conversation and all its associated items.
|
||||
|
||||
**Path Parameters:**
|
||||
- `conversation_id` (string, required): The conversation ID
|
||||
|
||||
**Response:**
|
||||
```
|
||||
204 No Content
|
||||
```
|
||||
|
||||
**Example:**
|
||||
```bash
|
||||
curl -X DELETE http://localhost:8080/v1/conversations/conv_123 \
|
||||
-H "Authorization: Bearer <token>"
|
||||
```
|
||||
|
||||
## Conversation Items (Messages)
|
||||
|
||||
### List Items in Conversation
|
||||
|
||||
**Endpoint**: `GET /v1/conversations/{conversation_id}/items`
|
||||
|
||||
Retrieves all items (messages) in a specific conversation.
|
||||
|
||||
**Path Parameters:**
|
||||
- `conversation_id` (string, required): The conversation ID
|
||||
|
||||
**Query Parameters:**
|
||||
- `limit` (integer, optional): Number of items to return (1-100, default: 20)
|
||||
- `offset` (integer, optional): Number of items to skip (default: 0)
|
||||
|
||||
**Response:**
|
||||
```json
|
||||
{
|
||||
"items": [
|
||||
{
|
||||
"id": "item_001",
|
||||
"conversation_id": "conv_123",
|
||||
"role": "user",
|
||||
"content": "Hello, can you help me with machine learning?",
|
||||
"created_at": "2024-01-01T12:00:00Z",
|
||||
"metadata": {
|
||||
"tokens": 12
|
||||
}
|
||||
},
|
||||
{
|
||||
"id": "item_002",
|
||||
"conversation_id": "conv_123",
|
||||
"role": "assistant",
|
||||
"content": "Of course! I'd be happy to help you with machine learning. What specific aspect would you like to learn about?",
|
||||
"created_at": "2024-01-01T12:01:00Z",
|
||||
"metadata": {
|
||||
"tokens": 25,
|
||||
"model": "jan-v1-4b"
|
||||
}
|
||||
}
|
||||
],
|
||||
"total": 2,
|
||||
"limit": 20,
|
||||
"offset": 0
|
||||
}
|
||||
```
|
||||
|
||||
**Example:**
|
||||
```bash
|
||||
curl -H "Authorization: Bearer <token>" \
|
||||
"http://localhost:8080/v1/conversations/conv_123/items?limit=50"
|
||||
```
|
||||
|
||||
### Create Items in Conversation
|
||||
|
||||
**Endpoint**: `POST /v1/conversations/{conversation_id}/items`
|
||||
|
||||
Adds new items (messages) to a conversation.
|
||||
|
||||
**Path Parameters:**
|
||||
- `conversation_id` (string, required): The conversation ID
|
||||
|
||||
**Request Body:**
|
||||
```json
|
||||
{
|
||||
"items": [
|
||||
{
|
||||
"role": "user",
|
||||
"content": "What is supervised learning?",
|
||||
"metadata": {
|
||||
"tokens": 6
|
||||
}
|
||||
},
|
||||
{
|
||||
"role": "assistant",
|
||||
"content": "Supervised learning is a type of machine learning where algorithms learn from labeled training data to make predictions on new, unseen data.",
|
||||
"metadata": {
|
||||
"tokens": 28,
|
||||
"model": "jan-v1-4b"
|
||||
}
|
||||
}
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
**Response:**
|
||||
```json
|
||||
{
|
||||
"items": [
|
||||
{
|
||||
"id": "item_003",
|
||||
"conversation_id": "conv_123",
|
||||
"role": "user",
|
||||
"content": "What is supervised learning?",
|
||||
"created_at": "2024-01-01T12:02:00Z",
|
||||
"metadata": {
|
||||
"tokens": 6
|
||||
}
|
||||
},
|
||||
{
|
||||
"id": "item_004",
|
||||
"conversation_id": "conv_123",
|
||||
"role": "assistant",
|
||||
"content": "Supervised learning is a type of machine learning where algorithms learn from labeled training data to make predictions on new, unseen data.",
|
||||
"created_at": "2024-01-01T12:02:30Z",
|
||||
"metadata": {
|
||||
"tokens": 28,
|
||||
"model": "jan-v1-4b"
|
||||
}
|
||||
}
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
**Example:**
|
||||
```bash
|
||||
curl -X POST http://localhost:8080/v1/conversations/conv_123/items \
|
||||
-H "Authorization: Bearer <token>" \
|
||||
-H "Content-Type: application/json" \
|
||||
-d '{
|
||||
"items": [
|
||||
{
|
||||
"role": "user",
|
||||
"content": "What is supervised learning?"
|
||||
},
|
||||
{
|
||||
"role": "assistant",
|
||||
"content": "Supervised learning is a type of machine learning..."
|
||||
}
|
||||
]
|
||||
}'
|
||||
```
|
||||
|
||||
### Get Item from Conversation
|
||||
|
||||
**Endpoint**: `GET /v1/conversations/{conversation_id}/items/{item_id}`
|
||||
|
||||
Retrieves a specific item from a conversation.
|
||||
|
||||
**Path Parameters:**
|
||||
- `conversation_id` (string, required): The conversation ID
|
||||
- `item_id` (string, required): The item ID
|
||||
|
||||
**Response:**
|
||||
```json
|
||||
{
|
||||
"id": "item_001",
|
||||
"conversation_id": "conv_123",
|
||||
"role": "user",
|
||||
"content": "Hello, can you help me with machine learning?",
|
||||
"created_at": "2024-01-01T12:00:00Z",
|
||||
"metadata": {
|
||||
"tokens": 12
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
**Example:**
|
||||
```bash
|
||||
curl -H "Authorization: Bearer <token>" \
|
||||
http://localhost:8080/v1/conversations/conv_123/items/item_001
|
||||
```
|
||||
|
||||
### Delete Item from Conversation
|
||||
|
||||
**Endpoint**: `DELETE /v1/conversations/{conversation_id}/items/{item_id}`
|
||||
|
||||
Removes a specific item from a conversation.
|
||||
|
||||
**Path Parameters:**
|
||||
- `conversation_id` (string, required): The conversation ID
|
||||
- `item_id` (string, required): The item ID
|
||||
|
||||
**Response:**
|
||||
```
|
||||
204 No Content
|
||||
```
|
||||
|
||||
**Example:**
|
||||
```bash
|
||||
curl -X DELETE http://localhost:8080/v1/conversations/conv_123/items/item_001 \
|
||||
-H "Authorization: Bearer <token>"
|
||||
```
|
||||
|
||||
## Data Models
|
||||
|
||||
### Conversation Object
|
||||
|
||||
```json
|
||||
{
|
||||
"id": "string",
|
||||
"title": "string",
|
||||
"model": "string",
|
||||
"created_at": "datetime",
|
||||
"updated_at": "datetime",
|
||||
"item_count": "integer",
|
||||
"user_id": "string",
|
||||
"metadata": "object"
|
||||
}
|
||||
```
|
||||
|
||||
### Item Object
|
||||
|
||||
```json
|
||||
{
|
||||
"id": "string",
|
||||
"conversation_id": "string",
|
||||
"role": "user|assistant|system",
|
||||
"content": "string",
|
||||
"created_at": "datetime",
|
||||
"metadata": "object"
|
||||
}
|
||||
```
|
||||
|
||||
## Error Responses
|
||||
|
||||
### Common Error Codes
|
||||
|
||||
| Status Code | Description |
|
||||
|-------------|-------------|
|
||||
| `400` | Bad Request - Invalid request format or parameters |
|
||||
| `401` | Unauthorized - Invalid or missing authentication |
|
||||
| `403` | Forbidden - Insufficient permissions |
|
||||
| `404` | Not Found - Conversation or item not found |
|
||||
| `429` | Too Many Requests - Rate limit exceeded |
|
||||
| `500` | Internal Server Error - Server error |
|
||||
|
||||
### Error Response Format
|
||||
|
||||
```json
|
||||
{
|
||||
"error": {
|
||||
"message": "Conversation not found",
|
||||
"type": "not_found_error",
|
||||
"code": "conversation_not_found"
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
## Best Practices
|
||||
|
||||
### Conversation Management
|
||||
|
||||
1. **Use Descriptive Titles**: Create meaningful conversation titles for easy identification
|
||||
2. **Organize with Metadata**: Use metadata to categorize and tag conversations
|
||||
3. **Regular Cleanup**: Delete old conversations to manage storage
|
||||
4. **Batch Operations**: Use bulk operations when adding multiple items
|
||||
|
||||
### Performance Optimization
|
||||
|
||||
1. **Pagination**: Use limit and offset for large conversation lists
|
||||
2. **Selective Loading**: Load only necessary conversation data
|
||||
3. **Caching**: Cache frequently accessed conversations
|
||||
4. **Indexing**: Use metadata for efficient conversation filtering
|
||||
|
||||
## Rate Limiting
|
||||
|
||||
Conversation endpoints have the following rate limits:
|
||||
- **List/Get operations**: 100 requests per minute
|
||||
- **Create/Update operations**: 50 requests per minute
|
||||
- **Delete operations**: 20 requests per minute
|
||||
|
||||
Rate limit headers are included in responses:
|
||||
```
|
||||
X-RateLimit-Limit: 100
|
||||
X-RateLimit-Remaining: 99
|
||||
X-RateLimit-Reset: 1609459200
|
||||
```
|
||||
@ -1,525 +0,0 @@
|
||||
---
|
||||
title: Responses API
|
||||
description: Advanced response operations for managing AI response lifecycle and metadata.
|
||||
---
|
||||
|
||||
## Overview
|
||||
|
||||
The Jan-Responses API provides advanced endpoints for managing AI response lifecycle, including response creation, retrieval, cancellation, and comprehensive input item management. This API is designed for applications that require detailed control over response processing and metadata tracking.
|
||||
|
||||
## Endpoints
|
||||
|
||||
### Create Response
|
||||
|
||||
**Endpoint**: `POST /v1/responses`
|
||||
|
||||
Creates a new AI response with comprehensive configuration options and input item management.
|
||||
|
||||
**Request Body:**
|
||||
```json
|
||||
{
|
||||
"model": "jan-v1-4b",
|
||||
"messages": [
|
||||
{
|
||||
"role": "user",
|
||||
"content": "Analyze the following data and provide insights"
|
||||
}
|
||||
],
|
||||
"parameters": {
|
||||
"max_tokens": 1000,
|
||||
"temperature": 0.7,
|
||||
"stream": false,
|
||||
"top_p": 0.9,
|
||||
"frequency_penalty": 0.0,
|
||||
"presence_penalty": 0.0
|
||||
},
|
||||
"metadata": {
|
||||
"session_id": "sess_456",
|
||||
"user_context": "data_analyst",
|
||||
"priority": "high",
|
||||
"tags": ["analysis", "data", "insights"]
|
||||
},
|
||||
"input_items": [
|
||||
{
|
||||
"role": "user",
|
||||
"content": "Analyze the following data and provide insights",
|
||||
"metadata": {
|
||||
"source": "user_input",
|
||||
"language": "en"
|
||||
}
|
||||
}
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
**Parameters:**
|
||||
- `model` (string, required): Model identifier for the response
|
||||
- `messages` (array, required): Array of input messages
|
||||
- `parameters` (object, optional): Advanced model parameters
|
||||
- `metadata` (object, optional): Comprehensive response metadata
|
||||
- `input_items` (array, optional): Detailed input item specifications
|
||||
|
||||
**Response:**
|
||||
```json
|
||||
{
|
||||
"id": "resp_abc123",
|
||||
"model": "jan-v1-4b",
|
||||
"status": "processing",
|
||||
"created_at": "2024-01-01T12:00:00Z",
|
||||
"updated_at": "2024-01-01T12:00:00Z",
|
||||
"metadata": {
|
||||
"session_id": "sess_456",
|
||||
"user_context": "data_analyst",
|
||||
"priority": "high",
|
||||
"tags": ["analysis", "data", "insights"]
|
||||
},
|
||||
"input_items": [
|
||||
{
|
||||
"id": "item_001",
|
||||
"response_id": "resp_abc123",
|
||||
"role": "user",
|
||||
"content": "Analyze the following data and provide insights",
|
||||
"created_at": "2024-01-01T12:00:00Z",
|
||||
"metadata": {
|
||||
"source": "user_input",
|
||||
"language": "en"
|
||||
}
|
||||
}
|
||||
],
|
||||
"processing_info": {
|
||||
"estimated_completion_time": "2024-01-01T12:02:00Z",
|
||||
"queue_position": 1,
|
||||
"priority_score": 85
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
**Example:**
|
||||
```bash
|
||||
curl -X POST http://localhost:8080/v1/responses \
|
||||
-H "Authorization: Bearer <token>" \
|
||||
-H "Content-Type: application/json" \
|
||||
-d '{
|
||||
"model": "jan-v1-4b",
|
||||
"messages": [
|
||||
{"role": "user", "content": "Analyze the following data and provide insights"}
|
||||
],
|
||||
"parameters": {
|
||||
"max_tokens": 1000,
|
||||
"temperature": 0.7
|
||||
},
|
||||
"metadata": {
|
||||
"session_id": "sess_456",
|
||||
"priority": "high",
|
||||
"tags": ["analysis", "data"]
|
||||
}
|
||||
}'
|
||||
```
|
||||
|
||||
### Get Response
|
||||
|
||||
**Endpoint**: `GET /v1/responses/{response_id}`
|
||||
|
||||
Retrieves comprehensive details of a specific response including status, content, metadata, and processing information.
|
||||
|
||||
**Path Parameters:**
|
||||
- `response_id` (string, required): The response ID
|
||||
|
||||
**Query Parameters:**
|
||||
- `include_metadata` (boolean, optional): Include detailed metadata (default: true)
|
||||
- `include_input_items` (boolean, optional): Include input items (default: true)
|
||||
- `include_usage` (boolean, optional): Include usage statistics (default: true)
|
||||
|
||||
**Response:**
|
||||
```json
|
||||
{
|
||||
"id": "resp_abc123",
|
||||
"model": "jan-v1-4b",
|
||||
"status": "completed",
|
||||
"created_at": "2024-01-01T12:00:00Z",
|
||||
"updated_at": "2024-01-01T12:03:45Z",
|
||||
"completed_at": "2024-01-01T12:03:45Z",
|
||||
"metadata": {
|
||||
"session_id": "sess_456",
|
||||
"user_context": "data_analyst",
|
||||
"priority": "high",
|
||||
"tags": ["analysis", "data", "insights"],
|
||||
"processing_time_ms": 225000,
|
||||
"model_version": "v1.2.3"
|
||||
},
|
||||
"content": {
|
||||
"text": "Based on the provided data, I can identify several key insights...",
|
||||
"format": "text",
|
||||
"confidence_score": 0.92,
|
||||
"sentiment": "neutral"
|
||||
},
|
||||
"usage": {
|
||||
"prompt_tokens": 25,
|
||||
"completion_tokens": 450,
|
||||
"total_tokens": 475,
|
||||
"cost": 0.001425,
|
||||
"efficiency_score": 0.89
|
||||
},
|
||||
"input_items": [
|
||||
{
|
||||
"id": "item_001",
|
||||
"response_id": "resp_abc123",
|
||||
"role": "user",
|
||||
"content": "Analyze the following data and provide insights",
|
||||
"created_at": "2024-01-01T12:00:00Z",
|
||||
"metadata": {
|
||||
"source": "user_input",
|
||||
"language": "en",
|
||||
"tokens": 12
|
||||
}
|
||||
}
|
||||
],
|
||||
"quality_metrics": {
|
||||
"coherence_score": 0.94,
|
||||
"relevance_score": 0.91,
|
||||
"completeness_score": 0.88,
|
||||
"accuracy_score": 0.93
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
**Example:**
|
||||
```bash
|
||||
curl -H "Authorization: Bearer <token>" \
|
||||
"http://localhost:8080/v1/responses/resp_abc123?include_metadata=true&include_usage=true"
|
||||
```
|
||||
|
||||
### Delete Response
|
||||
|
||||
**Endpoint**: `DELETE /v1/responses/{response_id}`
|
||||
|
||||
Permanently deletes a response and all its associated data, including input items and metadata.
|
||||
|
||||
**Path Parameters:**
|
||||
- `response_id` (string, required): The response ID
|
||||
|
||||
**Query Parameters:**
|
||||
- `force` (boolean, optional): Force deletion even if response is processing (default: false)
|
||||
|
||||
**Response:**
|
||||
```
|
||||
204 No Content
|
||||
```
|
||||
|
||||
**Example:**
|
||||
```bash
|
||||
curl -X DELETE http://localhost:8080/v1/responses/resp_abc123 \
|
||||
-H "Authorization: Bearer <token>"
|
||||
```
|
||||
|
||||
### Cancel Response
|
||||
|
||||
**Endpoint**: `POST /v1/responses/{response_id}/cancel`
|
||||
|
||||
Cancels a response that is currently being processed with detailed cancellation information.
|
||||
|
||||
**Path Parameters:**
|
||||
- `response_id` (string, required): The response ID
|
||||
|
||||
**Request Body:**
|
||||
```json
|
||||
{
|
||||
"reason": "user_requested",
|
||||
"message": "User cancelled the request"
|
||||
}
|
||||
```
|
||||
|
||||
**Response:**
|
||||
```json
|
||||
{
|
||||
"id": "resp_abc123",
|
||||
"status": "cancelled",
|
||||
"updated_at": "2024-01-01T12:01:30Z",
|
||||
"cancelled_at": "2024-01-01T12:01:30Z",
|
||||
"cancellation_info": {
|
||||
"reason": "user_requested",
|
||||
"message": "User cancelled the request",
|
||||
"processing_time_ms": 90000
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
**Example:**
|
||||
```bash
|
||||
curl -X POST http://localhost:8080/v1/responses/resp_abc123/cancel \
|
||||
-H "Authorization: Bearer <token>" \
|
||||
-H "Content-Type: application/json" \
|
||||
-d '{
|
||||
"reason": "user_requested",
|
||||
"message": "User cancelled the request"
|
||||
}'
|
||||
```
|
||||
|
||||
### List Input Items
|
||||
|
||||
**Endpoint**: `GET /v1/responses/{response_id}/input_items`
|
||||
|
||||
Retrieves all input items associated with a specific response with detailed metadata and analysis.
|
||||
|
||||
**Path Parameters:**
|
||||
- `response_id` (string, required): The response ID
|
||||
|
||||
**Query Parameters:**
|
||||
- `limit` (integer, optional): Number of items to return (1-100, default: 20)
|
||||
- `offset` (integer, optional): Number of items to skip (default: 0)
|
||||
- `include_metadata` (boolean, optional): Include item metadata (default: true)
|
||||
- `include_analysis` (boolean, optional): Include item analysis (default: false)
|
||||
|
||||
**Response:**
|
||||
```json
|
||||
{
|
||||
"input_items": [
|
||||
{
|
||||
"id": "item_001",
|
||||
"response_id": "resp_abc123",
|
||||
"role": "user",
|
||||
"content": "Analyze the following data and provide insights",
|
||||
"created_at": "2024-01-01T12:00:00Z",
|
||||
"metadata": {
|
||||
"source": "user_input",
|
||||
"language": "en",
|
||||
"tokens": 12,
|
||||
"complexity": "medium"
|
||||
},
|
||||
"analysis": {
|
||||
"sentiment": "neutral",
|
||||
"intent": "analysis_request",
|
||||
"entities": ["data", "insights"],
|
||||
"confidence": 0.95
|
||||
}
|
||||
},
|
||||
{
|
||||
"id": "item_002",
|
||||
"response_id": "resp_abc123",
|
||||
"role": "system",
|
||||
"content": "You are a data analysis expert. Provide detailed insights based on the data provided.",
|
||||
"created_at": "2024-01-01T12:00:00Z",
|
||||
"metadata": {
|
||||
"source": "system_prompt",
|
||||
"language": "en",
|
||||
"tokens": 20,
|
||||
"type": "instruction"
|
||||
}
|
||||
}
|
||||
],
|
||||
"total": 2,
|
||||
"limit": 20,
|
||||
"offset": 0,
|
||||
"summary": {
|
||||
"total_tokens": 32,
|
||||
"average_complexity": "medium",
|
||||
"primary_intent": "analysis_request"
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
**Example:**
|
||||
```bash
|
||||
curl -H "Authorization: Bearer <token>" \
|
||||
"http://localhost:8080/v1/responses/resp_abc123/input_items?include_analysis=true&limit=50"
|
||||
```
|
||||
|
||||
## Advanced Features
|
||||
|
||||
### Response Lifecycle Management
|
||||
|
||||
#### Status Tracking
|
||||
|
||||
- **`queued`**: Response is queued for processing
|
||||
- **`processing`**: Response is being generated
|
||||
- **`completed`**: Response has been successfully generated
|
||||
- **`failed`**: Response generation failed
|
||||
- **`cancelled`**: Response was cancelled before completion
|
||||
- **`timeout`**: Response generation timed out
|
||||
- **`retrying`**: Response is being retried after failure
|
||||
|
||||
#### Progress Tracking
|
||||
|
||||
```json
|
||||
{
|
||||
"progress": {
|
||||
"current_step": "generating_content",
|
||||
"completion_percentage": 75,
|
||||
"estimated_remaining_time_ms": 30000,
|
||||
"steps_completed": [
|
||||
"input_validation",
|
||||
"model_loading",
|
||||
"context_preparation"
|
||||
]
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
### Quality Metrics
|
||||
|
||||
#### Response Quality Assessment
|
||||
|
||||
```json
|
||||
{
|
||||
"quality_metrics": {
|
||||
"coherence_score": 0.94,
|
||||
"relevance_score": 0.91,
|
||||
"completeness_score": 0.88,
|
||||
"accuracy_score": 0.93,
|
||||
"overall_quality": 0.92,
|
||||
"quality_grade": "A"
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
#### Content Analysis
|
||||
|
||||
```json
|
||||
{
|
||||
"content_analysis": {
|
||||
"sentiment": "positive",
|
||||
"confidence_score": 0.92,
|
||||
"readability_score": 0.87,
|
||||
"technical_complexity": "medium",
|
||||
"key_topics": ["data analysis", "insights", "patterns"],
|
||||
"language": "en"
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
### Metadata Management
|
||||
|
||||
#### Standard Metadata Fields
|
||||
|
||||
- **`session_id`**: Links response to a user session
|
||||
- **`user_context`**: Additional context about the user
|
||||
- **`request_source`**: Source of the request (web, api, mobile)
|
||||
- **`priority`**: Response priority level (low, medium, high, urgent)
|
||||
- **`tags`**: Array of tags for categorization
|
||||
- **`processing_time_ms`**: Time taken to process the response
|
||||
- **`model_version`**: Version of the model used
|
||||
|
||||
#### Custom Metadata
|
||||
|
||||
```json
|
||||
{
|
||||
"metadata": {
|
||||
"session_id": "sess_456",
|
||||
"user_context": "data_analyst",
|
||||
"priority": "high",
|
||||
"tags": ["analysis", "data", "insights"],
|
||||
"custom_field": "custom_value",
|
||||
"business_context": "quarterly_report",
|
||||
"department": "analytics"
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
### Input Item Analysis
|
||||
|
||||
#### Item Metadata
|
||||
|
||||
```json
|
||||
{
|
||||
"metadata": {
|
||||
"source": "user_input|system_prompt|context",
|
||||
"language": "en",
|
||||
"tokens": 12,
|
||||
"complexity": "low|medium|high",
|
||||
"type": "question|instruction|data",
|
||||
"confidence": 0.95
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
#### Item Analysis
|
||||
|
||||
```json
|
||||
{
|
||||
"analysis": {
|
||||
"sentiment": "positive|negative|neutral",
|
||||
"intent": "analysis_request|question|instruction",
|
||||
"entities": ["entity1", "entity2"],
|
||||
"confidence": 0.95,
|
||||
"complexity_score": 0.7
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
## Error Responses
|
||||
|
||||
### Common Error Codes
|
||||
|
||||
| Status Code | Description |
|
||||
|-------------|-------------|
|
||||
| `400` | Bad Request - Invalid request format or parameters |
|
||||
| `401` | Unauthorized - Invalid or missing authentication |
|
||||
| `404` | Not Found - Response not found |
|
||||
| `409` | Conflict - Response cannot be cancelled (already completed) |
|
||||
| `422` | Unprocessable Entity - Invalid input data |
|
||||
| `429` | Too Many Requests - Rate limit exceeded |
|
||||
| `500` | Internal Server Error - Server error |
|
||||
| `503` | Service Unavailable - Model service unavailable |
|
||||
|
||||
### Error Response Format
|
||||
|
||||
```json
|
||||
{
|
||||
"error": {
|
||||
"message": "Response not found",
|
||||
"type": "not_found_error",
|
||||
"code": "response_not_found",
|
||||
"response_id": "resp_abc123",
|
||||
"details": {
|
||||
"suggestion": "Check if the response ID is correct",
|
||||
"documentation": "https://docs.jan.ai/api-reference"
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
## Best Practices
|
||||
|
||||
### Response Management
|
||||
|
||||
1. **Monitor Status**: Implement real-time status monitoring for long-running requests
|
||||
2. **Handle Cancellation**: Provide clear cancellation options for users
|
||||
3. **Store Metadata**: Use comprehensive metadata for tracking and analytics
|
||||
4. **Quality Assurance**: Monitor quality metrics and implement feedback loops
|
||||
|
||||
### Performance Optimization
|
||||
|
||||
1. **Batch Operations**: Group related requests when possible
|
||||
2. **Async Processing**: Use async patterns for long-running responses
|
||||
3. **Caching**: Cache completed responses and metadata
|
||||
4. **Monitoring**: Track response times, success rates, and quality metrics
|
||||
|
||||
### Error Handling
|
||||
|
||||
1. **Retry Logic**: Implement intelligent retry logic for transient failures
|
||||
2. **Timeout Handling**: Set appropriate timeouts based on response complexity
|
||||
3. **Graceful Degradation**: Handle service unavailability gracefully
|
||||
4. **User Feedback**: Provide clear, actionable error messages
|
||||
|
||||
### Data Management
|
||||
|
||||
1. **Cleanup**: Implement automated cleanup of old responses
|
||||
2. **Backup**: Regular backup of important response data
|
||||
3. **Privacy**: Ensure proper handling of sensitive data in responses
|
||||
4. **Compliance**: Maintain compliance with data protection regulations
|
||||
|
||||
## Rate Limiting
|
||||
|
||||
Jan-Responses endpoints have the following rate limits:
|
||||
- **Create operations**: 15 requests per minute
|
||||
- **Get operations**: 100 requests per minute
|
||||
- **Cancel operations**: 10 requests per minute
|
||||
- **Delete operations**: 5 requests per minute
|
||||
- **List operations**: 200 requests per minute
|
||||
|
||||
Rate limit headers are included in responses:
|
||||
```
|
||||
X-RateLimit-Limit: 15
|
||||
X-RateLimit-Remaining: 14
|
||||
X-RateLimit-Reset: 1609459200
|
||||
```
|
||||
@ -1,141 +0,0 @@
|
||||
---
|
||||
title: Server API
|
||||
description: System administration and monitoring endpoints for Jan Server infrastructure.
|
||||
---
|
||||
|
||||
## Overview
|
||||
|
||||
The Jan Server API provides system administration and monitoring endpoints for managing the Jan Server infrastructure, including version information and basic health checks. These endpoints are essential for system administrators and monitoring tools.
|
||||
|
||||
## Endpoints
|
||||
|
||||
### Get API Build Version
|
||||
|
||||
**Endpoint**: `GET /v1/version`
|
||||
|
||||
Retrieves the current build version and environment reload timestamp of the Jan Server API.
|
||||
|
||||
**Response:**
|
||||
```json
|
||||
{
|
||||
"version": "dev",
|
||||
"env_reloaded_at": "2024-01-01T12:00:00Z"
|
||||
}
|
||||
```
|
||||
|
||||
**Response Fields:**
|
||||
- `version` (string): Current version of the API server (defaults to "dev")
|
||||
- `env_reloaded_at` (string): ISO timestamp when environment variables were last reloaded
|
||||
|
||||
**Example:**
|
||||
```bash
|
||||
curl http://localhost:8080/v1/version
|
||||
```
|
||||
|
||||
## System Information
|
||||
|
||||
### Version Information
|
||||
|
||||
The version endpoint provides basic system information:
|
||||
|
||||
- **Version**: Current version of the API server (typically "dev" in development)
|
||||
- **Environment Reload**: Timestamp when environment variables were last loaded/reloaded
|
||||
|
||||
### Environment Variables
|
||||
|
||||
The system loads configuration from environment variables including:
|
||||
- Database connection strings
|
||||
- JWT secrets and OAuth2 credentials
|
||||
- API keys for external services
|
||||
- CORS and SMTP settings
|
||||
|
||||
## Health Monitoring
|
||||
|
||||
### Health Check Endpoint
|
||||
|
||||
**Endpoint**: `GET /healthcheck`
|
||||
|
||||
Basic health check for load balancers and monitoring systems.
|
||||
|
||||
**Response:**
|
||||
```json
|
||||
"ok"
|
||||
```
|
||||
|
||||
**Example:**
|
||||
```bash
|
||||
curl http://localhost:8080/healthcheck
|
||||
```
|
||||
|
||||
## Error Responses
|
||||
|
||||
### Common Error Codes
|
||||
|
||||
| Status Code | Description |
|
||||
|-------------|-------------|
|
||||
| `400` | Bad Request - Invalid request format or parameters |
|
||||
| `401` | Unauthorized - Invalid or missing authentication |
|
||||
| `403` | Forbidden - Insufficient permissions |
|
||||
| `404` | Not Found - Resource not found |
|
||||
| `429` | Too Many Requests - Rate limit exceeded |
|
||||
| `500` | Internal Server Error - Server error |
|
||||
| `503` | Service Unavailable - Service temporarily unavailable |
|
||||
|
||||
### Error Response Format
|
||||
|
||||
```json
|
||||
{
|
||||
"error": {
|
||||
"message": "Insufficient permissions",
|
||||
"type": "forbidden_error",
|
||||
"code": "admin_required",
|
||||
"details": {
|
||||
"required_role": "admin",
|
||||
"current_role": "user"
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
## Best Practices
|
||||
|
||||
### System Monitoring
|
||||
|
||||
1. **Health Checks**: Implement regular health checks for all components
|
||||
2. **Version Tracking**: Keep track of component versions and updates
|
||||
3. **Dependency Monitoring**: Monitor external service dependencies
|
||||
4. **Logging**: Maintain detailed logs for troubleshooting
|
||||
|
||||
### Performance Monitoring
|
||||
|
||||
1. **Response Times**: Monitor API response times and set thresholds
|
||||
2. **Resource Usage**: Track CPU, memory, and GPU utilization
|
||||
3. **Error Rates**: Monitor error rates and implement alerting
|
||||
4. **Capacity Planning**: Use metrics for capacity planning and scaling
|
||||
|
||||
### Security
|
||||
|
||||
1. **Access Control**: Restrict admin endpoints to authorized users
|
||||
2. **Audit Logging**: Log all administrative actions
|
||||
3. **Configuration Security**: Secure configuration endpoints
|
||||
4. **Monitoring Access**: Monitor access to sensitive endpoints
|
||||
|
||||
### Maintenance
|
||||
|
||||
1. **Version Tracking**: Keep track of component versions and updates
|
||||
2. **Dependency Monitoring**: Monitor external service dependencies
|
||||
3. **Backup Verification**: Regularly verify system backups
|
||||
4. **Update Procedures**: Follow proper update and deployment procedures
|
||||
|
||||
## Rate Limiting
|
||||
|
||||
Jan Server system endpoints have the following rate limits:
|
||||
- **Version endpoint**: Standard rate limits apply
|
||||
- **Health check endpoint**: Standard rate limits apply
|
||||
|
||||
Rate limit headers are included in responses when applicable:
|
||||
```
|
||||
X-RateLimit-Limit: 100
|
||||
X-RateLimit-Remaining: 99
|
||||
X-RateLimit-Reset: 1609459200
|
||||
```
|
||||
@ -1,458 +0,0 @@
|
||||
---
|
||||
title: API Reference
|
||||
description: Complete API documentation for Jan Server endpoints organized by functionality.
|
||||
---
|
||||
|
||||
## Overview
|
||||
|
||||
Jan Server provides a comprehensive API gateway for AI model interactions with enterprise-grade features. It offers OpenAI-compatible endpoints, multi-tenant organization management, conversation handling, and comprehensive response tracking. The system serves as a centralized gateway for AI model interactions with features including user management, organization hierarchies, project-based access control, and real-time streaming responses.
|
||||
|
||||
### Key API Features
|
||||
|
||||
- **OpenAI-Compatible API**: Full compatibility with OpenAI's chat completion API with streaming support and reasoning content handling
|
||||
- **Multi-Tenant Architecture**: Organization and project-based access control with hierarchical permissions and member management
|
||||
- **Conversation Management**: Persistent conversation storage and retrieval with item-level management, including message, function call, and reasoning content types
|
||||
- **Authentication & Authorization**: JWT-based auth with Google OAuth2 integration and role-based access control
|
||||
- **API Key Management**: Secure API key generation and management at organization and project levels with multiple key types (admin, project, organization, service, ephemeral)
|
||||
- **Model Registry**: Dynamic model endpoint management with automatic health checking and service discovery
|
||||
- **Streaming Support**: Real-time streaming responses with Server-Sent Events (SSE) and chunked transfer encoding
|
||||
- **MCP Integration**: Model Context Protocol support for external tools and resources with JSON-RPC 2.0
|
||||
- **Web Search**: Serper API integration for web search capabilities via MCP with webpage fetching
|
||||
- **Response Management**: Comprehensive response tracking with status management and usage statistics
|
||||
|
||||
## Base URL
|
||||
|
||||
All API endpoints are available at the API gateway base URL:
|
||||
|
||||
```
|
||||
http://localhost:8080/v1
|
||||
```
|
||||
|
||||
The API gateway automatically forwards port 8080 when using the standard deployment scripts.
|
||||
|
||||
## API Sections
|
||||
|
||||
The Jan Server API is organized into the following functional areas:
|
||||
|
||||
### [Authentication](/server/api-reference-authentication)
|
||||
User authentication and authorization endpoints (`/v1/auth`):
|
||||
- Google OAuth2 callback handler (`POST /google/callback`)
|
||||
- Google OAuth2 login URL (`GET /google/login`)
|
||||
- User profile management (`GET /me`)
|
||||
- JWT token refresh (`GET /refresh-token`)
|
||||
- Guest login functionality (`POST /guest-login`)
|
||||
- User logout (`GET /logout`)
|
||||
|
||||
### [Completions API](/server/api-reference-chat)
|
||||
Core chat completion endpoints (`/v1/chat`, `/v1/mcp`, `/v1/models`):
|
||||
- OpenAI-compatible chat completions (`POST /chat/completions`)
|
||||
- Model Context Protocol (MCP) support (`POST /mcp`)
|
||||
- Model listing and information (`GET /models`)
|
||||
- Streaming responses with Server-Sent Events (SSE)
|
||||
- Supported MCP methods: initialize, notifications/initialized, ping, tools/list, tools/call, prompts/list, prompts/call, resources/list, resources/templates/list, resources/read, resources/subscribe
|
||||
|
||||
### [Chat Conversations](/server/api-reference-chat-conversations)
|
||||
Conversation-aware chat endpoints (`/v1/conv`):
|
||||
- Conversation-based chat completions (`POST /chat/completions`)
|
||||
- MCP streamable endpoint for conversations (`POST /mcp`)
|
||||
- Model information for conversation contexts (`GET /models`)
|
||||
- Streaming support with conversation persistence
|
||||
|
||||
### [Conversations API](/server/api-reference-conversations)
|
||||
Conversation management and persistence (`/v1/conversations`):
|
||||
- Create, read, update, delete conversations
|
||||
- Conversation item management (`POST /{conversation_id}/items`, `GET /{conversation_id}/items`)
|
||||
- Individual item operations (`GET /{conversation_id}/items/{item_id}`, `DELETE /{conversation_id}/items/{item_id}`)
|
||||
- Pagination support for large conversation histories
|
||||
|
||||
### [Administration API](/server/api-reference-administration)
|
||||
Multi-tenant organization management (`/v1/organization`):
|
||||
- Organization management (`GET /`, `POST /`, `GET /{org_id}`, `PATCH /{org_id}`, `DELETE /{org_id}`)
|
||||
- Organization API keys (`GET /{org_id}/api_keys`, `POST /{org_id}/api_keys`, `DELETE /{org_id}/api_keys/{key_id}`)
|
||||
- Admin API key management (`GET /admin_api_keys`, `POST /admin_api_keys`, `GET /admin_api_keys/{key_id}`, `DELETE /admin_api_keys/{key_id}`)
|
||||
- Project management (`GET /{org_id}/projects`, `POST /{org_id}/projects`, `GET /{org_id}/projects/{project_id}`, `PATCH /{org_id}/projects/{project_id}`, `DELETE /{org_id}/projects/{project_id}`)
|
||||
- Project API keys (`GET /{org_id}/projects/{project_id}/api_keys`, `POST /{org_id}/projects/{project_id}/api_keys`, `DELETE /{org_id}/projects/{project_id}/api_keys/{key_id}`)
|
||||
- Project archiving (`POST /{org_id}/projects/{project_id}/archive`)
|
||||
- Organization invites (`GET /{org_id}/invites`, `POST /{org_id}/invites`, `GET /{org_id}/invites/{invite_id}`, `DELETE /{org_id}/invites/{invite_id}`)
|
||||
- Hierarchical access control and permissions
|
||||
|
||||
### [Responses API](/server/api-reference-jan-responses)
|
||||
Advanced response operations (`/v1/responses`):
|
||||
- Response lifecycle management (`POST /`, `GET /{response_id}`, `DELETE /{response_id}`)
|
||||
- Response cancellation (`POST /{response_id}/cancel`)
|
||||
- Input item tracking (`GET /{response_id}/input_items`)
|
||||
- Comprehensive status management and usage statistics
|
||||
|
||||
### [Server API](/server/api-reference-jan-server)
|
||||
System administration and monitoring:
|
||||
- API version information (`GET /v1/version`)
|
||||
- System health and status (`GET /healthcheck`)
|
||||
- Development callback test (`GET /google/testcallback`)
|
||||
|
||||
## Authentication
|
||||
|
||||
Jan Server supports multiple authentication methods with role-based access control:
|
||||
|
||||
### JWT Token Authentication
|
||||
|
||||
JWT tokens provide stateless authentication with Google OAuth2 integration:
|
||||
|
||||
```bash
|
||||
curl -H "Authorization: Bearer <jwt_token>" \
|
||||
http://localhost:8080/v1/protected-endpoint
|
||||
```
|
||||
|
||||
### API Key Authentication
|
||||
|
||||
Multiple types of API keys with scoped permissions:
|
||||
- **Admin API Keys**: Organization-level administrative access
|
||||
- **Project API Keys**: Project-scoped access within organizations
|
||||
- **Organization API Keys**: Organization-wide access
|
||||
- **Service API Keys**: Service-to-service communication
|
||||
- **Ephemeral API Keys**: Temporary access tokens
|
||||
|
||||
```bash
|
||||
curl -H "Authorization: Bearer <api_key>" \
|
||||
http://localhost:8080/v1/protected-endpoint
|
||||
```
|
||||
|
||||
### Google OAuth2 Integration
|
||||
|
||||
Social authentication with Google OAuth2:
|
||||
1. Redirect to `/v1/auth/google/login` for OAuth URL
|
||||
2. Handle callback at `/v1/auth/google/callback`
|
||||
3. Exchange authorization code for JWT token
|
||||
4. Use JWT token for subsequent API calls
|
||||
|
||||
## API Usage Examples
|
||||
|
||||
### Chat Completion (OpenAI Compatible)
|
||||
|
||||
```bash
|
||||
curl -X POST http://localhost:8080/v1/chat/completions \
|
||||
-H "Content-Type: application/json" \
|
||||
-H "Authorization: Bearer YOUR_API_KEY" \
|
||||
-d '{
|
||||
"model": "jan-v1-4b",
|
||||
"messages": [
|
||||
{"role": "user", "content": "Hello, how are you?"}
|
||||
],
|
||||
"stream": true,
|
||||
"temperature": 0.7,
|
||||
"max_tokens": 1000
|
||||
}'
|
||||
```
|
||||
|
||||
### Conversation-based Chat Completion
|
||||
|
||||
```bash
|
||||
curl -X POST http://localhost:8080/v1/conv/chat/completions \
|
||||
-H "Content-Type: application/json" \
|
||||
-H "Authorization: Bearer YOUR_API_KEY" \
|
||||
-d '{
|
||||
"model": "jan-v1-4b",
|
||||
"input": "Hello, how are you?",
|
||||
"conversation_id": "conv_abc123",
|
||||
"stream": true,
|
||||
"temperature": 0.7,
|
||||
"max_tokens": 1000
|
||||
}'
|
||||
```
|
||||
|
||||
### Web Search via MCP
|
||||
|
||||
```bash
|
||||
curl -X POST http://localhost:8080/v1/mcp \
|
||||
-H "Content-Type: application/json" \
|
||||
-H "Authorization: Bearer YOUR_API_KEY" \
|
||||
-d '{
|
||||
"jsonrpc": "2.0",
|
||||
"id": 1,
|
||||
"method": "tools/call",
|
||||
"params": {
|
||||
"name": "serper_search",
|
||||
"arguments": {
|
||||
"q": "latest AI developments",
|
||||
"num": 5
|
||||
}
|
||||
}
|
||||
}'
|
||||
```
|
||||
|
||||
### Create Organization
|
||||
|
||||
```bash
|
||||
curl -X POST http://localhost:8080/v1/organization \
|
||||
-H "Content-Type: application/json" \
|
||||
-H "Authorization: Bearer YOUR_JWT_TOKEN" \
|
||||
-d '{
|
||||
"name": "My Organization",
|
||||
"description": "A sample organization"
|
||||
}'
|
||||
```
|
||||
|
||||
### Create API Key
|
||||
|
||||
```bash
|
||||
curl -X POST http://localhost:8080/v1/organization/{org_id}/api_keys \
|
||||
-H "Content-Type: application/json" \
|
||||
-H "Authorization: Bearer YOUR_JWT_TOKEN" \
|
||||
-d '{
|
||||
"name": "My API Key",
|
||||
"description": "API key for external integrations"
|
||||
}'
|
||||
```
|
||||
|
||||
### Create Project
|
||||
|
||||
```bash
|
||||
curl -X POST http://localhost:8080/v1/organization/{org_id}/projects \
|
||||
-H "Content-Type: application/json" \
|
||||
-H "Authorization: Bearer YOUR_JWT_TOKEN" \
|
||||
-d '{
|
||||
"name": "My Project",
|
||||
"description": "A sample project"
|
||||
}'
|
||||
```
|
||||
|
||||
### Create Conversation
|
||||
|
||||
```bash
|
||||
curl -X POST http://localhost:8080/v1/conversations \
|
||||
-H "Content-Type: application/json" \
|
||||
-H "Authorization: Bearer YOUR_API_KEY" \
|
||||
-d '{
|
||||
"title": "My Conversation",
|
||||
"description": "A sample conversation"
|
||||
}'
|
||||
```
|
||||
|
||||
### Add Item to Conversation
|
||||
|
||||
```bash
|
||||
curl -X POST http://localhost:8080/v1/conversations/{conversation_id}/items \
|
||||
-H "Content-Type: application/json" \
|
||||
-H "Authorization: Bearer YOUR_API_KEY" \
|
||||
-d '{
|
||||
"type": "message",
|
||||
"content": "Hello, how are you?",
|
||||
"role": "user"
|
||||
}'
|
||||
```
|
||||
|
||||
### Create Response
|
||||
|
||||
```bash
|
||||
curl -X POST http://localhost:8080/v1/responses \
|
||||
-H "Content-Type: application/json" \
|
||||
-H "Authorization: Bearer YOUR_API_KEY" \
|
||||
-d '{
|
||||
"model": "jan-v1-4b",
|
||||
"messages": [
|
||||
{"role": "user", "content": "Hello, how are you?"}
|
||||
],
|
||||
"temperature": 0.7,
|
||||
"max_tokens": 1000
|
||||
}'
|
||||
```
|
||||
|
||||
### Cancel Response
|
||||
|
||||
```bash
|
||||
curl -X POST http://localhost:8080/v1/responses/{response_id}/cancel \
|
||||
-H "Authorization: Bearer YOUR_API_KEY"
|
||||
```
|
||||
|
||||
## Interactive Documentation
|
||||
|
||||
Jan Server provides interactive Swagger documentation at:
|
||||
|
||||
```
|
||||
http://localhost:8080/api/swagger/index.html
|
||||
```
|
||||
|
||||
This interface allows you to:
|
||||
- Browse all available endpoints
|
||||
- Test API calls directly from the browser
|
||||
- View request/response schemas
|
||||
- Generate code samples
|
||||
|
||||
The Swagger documentation is auto-generated from Go code annotations and provides the most up-to-date API reference.
|
||||
|
||||
## API Structure Overview
|
||||
|
||||
The API is organized into the following main groups:
|
||||
|
||||
1. **Authentication API** - User authentication and authorization
|
||||
2. **Chat Completions API** - Chat completions, models, and MCP functionality
|
||||
3. **Conversation-aware Chat API** - Conversation-based chat completions
|
||||
4. **Conversations API** - Conversation management and items
|
||||
5. **Responses API** - Response tracking and management
|
||||
6. **Administration API** - Organization and project management
|
||||
7. **Server API** - System information and health checks
|
||||
|
||||
### Supported MCP Methods
|
||||
|
||||
The Model Context Protocol (MCP) integration supports the following methods:
|
||||
|
||||
- `initialize` - MCP initialization
|
||||
- `notifications/initialized` - Initialization notification
|
||||
- `ping` - Connection ping
|
||||
- `tools/list` - List available tools (Serper search, webpage fetch)
|
||||
- `tools/call` - Execute tool calls
|
||||
- `prompts/list` - List available prompts
|
||||
- `prompts/call` - Execute prompts
|
||||
- `resources/list` - List available resources
|
||||
- `resources/templates/list` - List resource templates
|
||||
- `resources/read` - Read resource content
|
||||
- `resources/subscribe` - Subscribe to resource updates
|
||||
|
||||
### API Key Types
|
||||
|
||||
Jan Server supports multiple types of API keys with different scopes:
|
||||
|
||||
- **Admin API Keys**: Organization-level administrative access
|
||||
- **Project API Keys**: Project-scoped access within organizations
|
||||
- **Organization API Keys**: Organization-wide access
|
||||
- **Service API Keys**: Service-to-service communication
|
||||
- **Ephemeral API Keys**: Temporary access tokens
|
||||
|
||||
## Error Responses
|
||||
|
||||
Jan Server returns standard HTTP status codes and JSON error responses:
|
||||
|
||||
```json
|
||||
{
|
||||
"error": {
|
||||
"message": "Invalid request format",
|
||||
"type": "invalid_request_error",
|
||||
"code": "invalid_json"
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
### Common Error Codes
|
||||
|
||||
| Status Code | Description |
|
||||
|-------------|-------------|
|
||||
| `400` | Bad Request - Invalid request format |
|
||||
| `401` | Unauthorized - Invalid or missing authentication |
|
||||
| `403` | Forbidden - Insufficient permissions |
|
||||
| `404` | Not Found - Resource not found |
|
||||
| `429` | Too Many Requests - Rate limit exceeded |
|
||||
| `500` | Internal Server Error - Server error |
|
||||
| `503` | Service Unavailable - Service temporarily unavailable |
|
||||
|
||||
## Rate Limiting
|
||||
|
||||
API endpoints implement rate limiting to prevent abuse:
|
||||
|
||||
- **Authenticated requests**: 1000 requests per hour per user
|
||||
- **Unauthenticated requests**: 100 requests per hour per IP
|
||||
- **Model inference**: 60 requests per minute per user
|
||||
|
||||
Rate limit headers are included in responses:
|
||||
```
|
||||
X-RateLimit-Limit: 1000
|
||||
X-RateLimit-Remaining: 999
|
||||
X-RateLimit-Reset: 1609459200
|
||||
```
|
||||
|
||||
## SDK and Client Libraries
|
||||
|
||||
### JavaScript/Node.js
|
||||
|
||||
Use the OpenAI JavaScript SDK with Jan Server:
|
||||
|
||||
```javascript
|
||||
import OpenAI from 'openai';
|
||||
|
||||
const openai = new OpenAI({
|
||||
baseURL: 'http://localhost:8080/v1',
|
||||
apiKey: 'your-jwt-token'
|
||||
});
|
||||
|
||||
const completion = await openai.chat.completions.create({
|
||||
model: 'jan-v1-4b',
|
||||
messages: [
|
||||
{ role: 'user', content: 'Hello!' }
|
||||
]
|
||||
});
|
||||
```
|
||||
|
||||
### Python
|
||||
|
||||
Use the OpenAI Python SDK:
|
||||
|
||||
```python
|
||||
import openai
|
||||
|
||||
openai.api_base = "http://localhost:8080/v1"
|
||||
openai.api_key = "your-jwt-token"
|
||||
|
||||
response = openai.ChatCompletion.create(
|
||||
model="jan-v1-4b",
|
||||
messages=[
|
||||
{"role": "user", "content": "Hello!"}
|
||||
]
|
||||
)
|
||||
```
|
||||
|
||||
### Go
|
||||
|
||||
Use the OpenAI Go SDK:
|
||||
|
||||
```go
|
||||
package main
|
||||
|
||||
import (
|
||||
"context"
|
||||
"fmt"
|
||||
"github.com/sashabaranov/go-openai"
|
||||
)
|
||||
|
||||
func main() {
|
||||
client := openai.NewClientWithConfig(openai.DefaultConfig("your-jwt-token"))
|
||||
client.BaseURL = "http://localhost:8080/v1"
|
||||
|
||||
resp, err := client.CreateChatCompletion(
|
||||
context.Background(),
|
||||
openai.ChatCompletionRequest{
|
||||
Model: "jan-v1-4b",
|
||||
Messages: []openai.ChatCompletionMessage{
|
||||
{
|
||||
Role: openai.ChatMessageRoleUser,
|
||||
Content: "Hello!",
|
||||
},
|
||||
},
|
||||
},
|
||||
)
|
||||
|
||||
if err != nil {
|
||||
fmt.Printf("ChatCompletion error: %v\n", err)
|
||||
return
|
||||
}
|
||||
|
||||
fmt.Println(resp.Choices[0].Message.Content)
|
||||
}
|
||||
```
|
||||
|
||||
### cURL with Streaming
|
||||
|
||||
For streaming responses:
|
||||
|
||||
```bash
|
||||
curl -X POST http://localhost:8080/v1/chat/completions \
|
||||
-H "Content-Type: application/json" \
|
||||
-H "Authorization: Bearer YOUR_API_KEY" \
|
||||
-H "Accept: text/event-stream" \
|
||||
-d '{
|
||||
"model": "jan-v1-4b",
|
||||
"messages": [
|
||||
{"role": "user", "content": "Tell me a story"}
|
||||
],
|
||||
"stream": true,
|
||||
"temperature": 0.7,
|
||||
"max_tokens": 1000
|
||||
}'
|
||||
```
|
||||
@ -1,336 +0,0 @@
|
||||
---
|
||||
title: Architecture
|
||||
description: Technical architecture and system design of Jan Server components.
|
||||
---
|
||||
|
||||
## System Overview
|
||||
|
||||
Jan Server is a comprehensive self-hosted AI server platform that provides OpenAI-compatible APIs, multi-tenant organization management, and AI model inference capabilities. Jan Server enables organizations to deploy their own private AI infrastructure with full control over data, models, and access.
|
||||
|
||||
Jan Server is a Kubernetes-native platform consisting of multiple microservices that work together to provide a complete AI infrastructure solution. It offers:
|
||||
|
||||
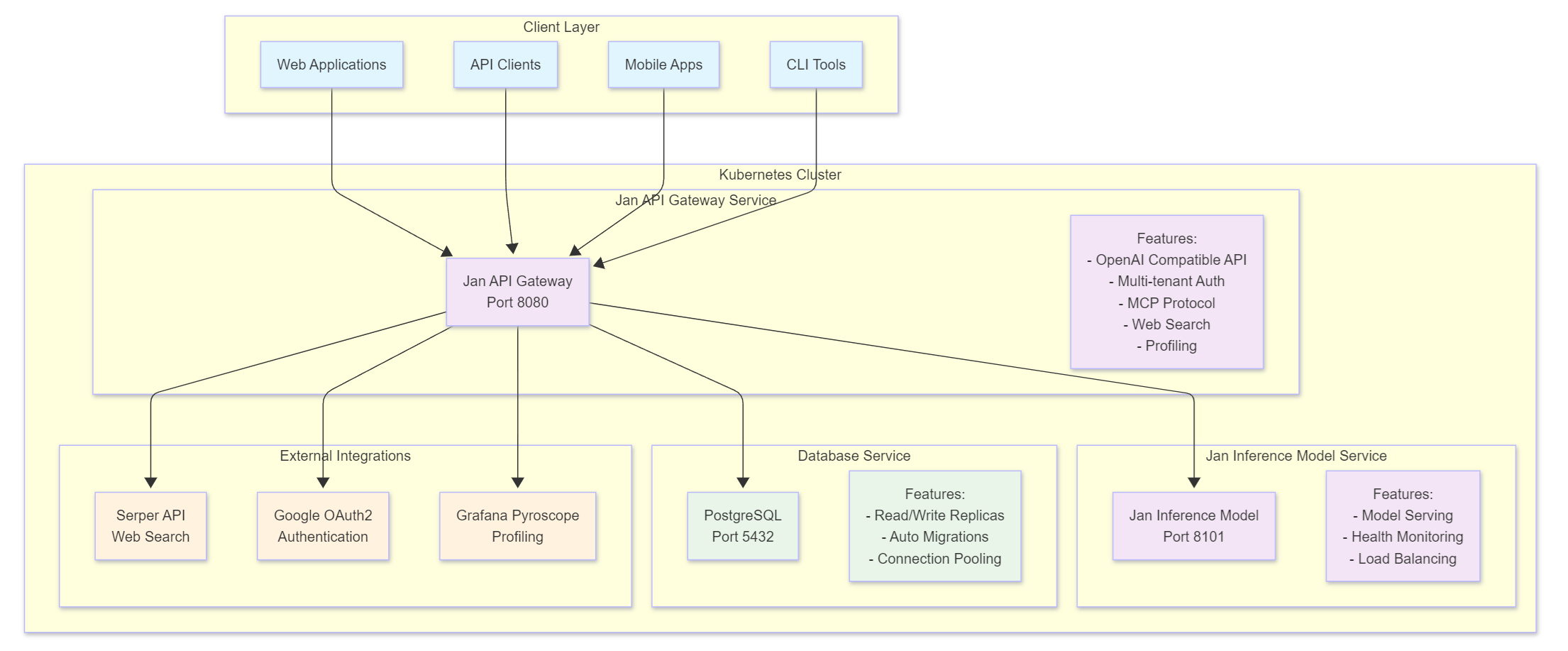
|
||||
|
||||
### Key Features
|
||||
- **OpenAI-Compatible API**: Full compatibility with OpenAI's chat completion API
|
||||
- **Multi-Tenant Architecture**: Organization and project-based access control
|
||||
- **AI Model Inference**: Scalable model serving with health monitoring
|
||||
- **Database Management**: PostgreSQL with read/write replicas
|
||||
- **Authentication & Authorization**: JWT + Google OAuth2 integration
|
||||
- **API Key Management**: Secure API key generation and management
|
||||
- **Model Context Protocol (MCP)**: Support for external tools and resources
|
||||
- **Web Search Integration**: Serper API integration for web search capabilities
|
||||
- **Monitoring & Profiling**: Built-in performance monitoring and health checks
|
||||
|
||||
## Business Domain Architecture
|
||||
|
||||
### Core Domain Models
|
||||
|
||||
#### User Management
|
||||
- **Users**: Support for both regular users and guest users with email-based authentication
|
||||
- **Organizations**: Multi-tenant organizations with owner/member roles and hierarchical access
|
||||
- **Projects**: Project-based resource isolation within organizations with member management
|
||||
- **Invites**: Email-based invitation system for organization and project membership
|
||||
|
||||
#### Authentication & Authorization
|
||||
- **API Keys**: Multiple types (admin, project, organization, service, ephemeral) with scoped permissions
|
||||
- **JWT Tokens**: Stateless authentication with Google OAuth2 integration
|
||||
- **Role-Based Access**: Hierarchical permissions from organization owners to project members
|
||||
|
||||
#### Conversation Management
|
||||
- **Conversations**: Persistent chat sessions with metadata and privacy controls
|
||||
- **Items**: Rich conversation items supporting messages, function calls, and reasoning content
|
||||
- **Content Types**: Support for text, images, files, and multimodal content with annotations
|
||||
- **Status Tracking**: Real-time status management (pending, in_progress, completed, failed, cancelled)
|
||||
|
||||
#### Response Management
|
||||
- **Responses**: Comprehensive tracking of AI model interactions with full parameter logging
|
||||
- **Streaming**: Real-time streaming with Server-Sent Events and chunked transfer encoding
|
||||
- **Usage Statistics**: Token usage tracking and performance metrics
|
||||
- **Error Handling**: Detailed error tracking with unique error codes
|
||||
|
||||
#### External Integrations
|
||||
- **Jan Inference Service**: Primary AI model inference backend with health monitoring
|
||||
- **Serper API**: Web search capabilities via MCP with search and webpage fetching
|
||||
- **SMTP**: Email notifications for invitations and system alerts
|
||||
- **Model Registry**: Dynamic model discovery and health checking
|
||||
|
||||
### Data Flow Architecture
|
||||
|
||||
1. **Request Processing**: HTTP requests → Authentication → Authorization → Business Logic
|
||||
2. **AI Inference**: Request → Jan Inference Service → Streaming Response → Database Storage
|
||||
3. **MCP Integration**: JSON-RPC 2.0 → Tool Execution → External APIs → Response Streaming
|
||||
4. **Health Monitoring**: Cron Jobs → Service Discovery → Model Registry Updates
|
||||
5. **Database Operations**: Read/Write Replicas → Transaction Management → Automatic Migrations
|
||||
|
||||
## Components
|
||||
|
||||
### Jan API Gateway
|
||||
|
||||
The core API service that provides OpenAI-compatible endpoints and manages all client interactions.
|
||||
|
||||
**Key Features:**
|
||||
- OpenAI-compatible chat completion API with streaming support
|
||||
- Multi-tenant organization and project management
|
||||
- JWT-based authentication with Google OAuth2 integration
|
||||
- API key management at organization and project levels
|
||||
- Model Context Protocol (MCP) support for external tools
|
||||
- Web search integration via Serper API
|
||||
- Comprehensive monitoring and profiling capabilities
|
||||
- Database transaction management with automatic rollback
|
||||
|
||||
**Technology Stack:**
|
||||
- **Backend**: Go 1.24.6
|
||||
- **Web Framework**: Gin v1.10.1
|
||||
- **Database**: PostgreSQL with GORM v1.30.1
|
||||
- **Database Features**:
|
||||
- Read/Write Replicas with GORM dbresolver
|
||||
- Automatic migrations with Atlas
|
||||
- Generated query interfaces with GORM Gen
|
||||
- **Authentication**: JWT v5.3.0 + Google OAuth2 v3.15.0
|
||||
- **API Documentation**: Swagger/OpenAPI v1.16.6
|
||||
- **Streaming**: Server-Sent Events (SSE) with chunked transfer
|
||||
- **Dependency Injection**: Google Wire v0.6.0
|
||||
- **Logging**: Logrus v1.9.3 with structured logging
|
||||
- **HTTP Client**: Resty v3.0.0-beta.3
|
||||
- **Profiling**:
|
||||
- Built-in pprof endpoints
|
||||
- Grafana Pyroscope Go integration v0.1.8
|
||||
- **Scheduling**: Crontab v1.2.0 for health checks
|
||||
- **MCP Protocol**: MCP-Go v0.37.0 for Model Context Protocol
|
||||
- **External Integrations**:
|
||||
- Jan Inference Service
|
||||
- Serper API (Web Search)
|
||||
- Google OAuth2
|
||||
- **Development Tools**:
|
||||
- Atlas for database migrations
|
||||
- GORM Gen for code generation
|
||||
- Swagger for API documentation
|
||||
|
||||
**Project Structure:**
|
||||
```
|
||||
jan-api-gateway/
|
||||
├── application/ # Go application code
|
||||
├── docker/ # Docker configuration
|
||||
└── README.md # Service-specific documentation
|
||||
```
|
||||
|
||||
### Jan Inference Model
|
||||
|
||||
The AI model serving service that handles model inference requests.
|
||||
|
||||
**Key Features:**
|
||||
- Scalable model serving infrastructure
|
||||
- Health monitoring and automatic failover
|
||||
- Load balancing across multiple model instances
|
||||
- Integration with various AI model backends
|
||||
|
||||
**Technology Stack:**
|
||||
- Python-based model serving
|
||||
- Docker containerization
|
||||
- Kubernetes-native deployment
|
||||
|
||||
**Project Structure:**
|
||||
```
|
||||
jan-inference-model/
|
||||
├── application/ # Python application code
|
||||
└── Dockerfile # Container configuration
|
||||
```
|
||||
|
||||
### PostgreSQL Database
|
||||
|
||||
The persistent data storage layer with enterprise-grade features.
|
||||
|
||||
**Key Features:**
|
||||
- Read/write replica support for high availability
|
||||
- Automatic schema migrations with Atlas
|
||||
- Connection pooling and optimization
|
||||
- Transaction management with rollback support
|
||||
|
||||
**Schema:**
|
||||
- User accounts and authentication
|
||||
- Conversation history and management
|
||||
- Project and organization management
|
||||
- API keys and access control
|
||||
- Response tracking and metadata
|
||||
|
||||
## Data Flow
|
||||
|
||||
### Request Processing
|
||||
|
||||
1. **Client Request**: HTTP request to API gateway on port 8080
|
||||
2. **Authentication**: JWT token validation or OAuth2 flow
|
||||
3. **Request Routing**: Gateway routes to appropriate handler
|
||||
4. **Database Operations**: GORM queries for user data/state
|
||||
5. **Inference Call**: HTTP request to model service on port 8101
|
||||
6. **Response Assembly**: Gateway combines results and returns to client
|
||||
|
||||
### Authentication Flow
|
||||
|
||||
**JWT Authentication:**
|
||||
1. User provides credentials
|
||||
2. Gateway validates against database
|
||||
3. JWT token issued with HMAC-SHA256 signing
|
||||
4. Subsequent requests include JWT in Authorization header
|
||||
|
||||
**OAuth2 Flow:**
|
||||
1. Client redirected to Google OAuth2
|
||||
2. Authorization code returned to redirect URL
|
||||
3. Gateway exchanges code for access token
|
||||
4. User profile retrieved from Google
|
||||
5. Local JWT token issued
|
||||
|
||||
## Deployment Architecture
|
||||
|
||||
### Kubernetes Resources
|
||||
|
||||
**Deployments:**
|
||||
- `jan-api-gateway`: Single replica Go application
|
||||
- `jan-inference-model`: Single replica VLLM server
|
||||
- `postgresql`: StatefulSet with persistent storage
|
||||
|
||||
**Services:**
|
||||
- `jan-api-gateway`: ClusterIP exposing port 8080
|
||||
- `jan-inference-model`: ClusterIP exposing port 8101
|
||||
- `postgresql`: ClusterIP exposing port 5432
|
||||
|
||||
**Configuration:**
|
||||
- Environment variables via Helm values
|
||||
- Secrets for sensitive data (JWT keys, OAuth credentials)
|
||||
- ConfigMaps for application settings
|
||||
|
||||
### Helm Chart Structure
|
||||
|
||||
The system uses Helm charts for deployment configuration:
|
||||
|
||||
```
|
||||
charts/
|
||||
├── umbrella-chart/ # Main deployment chart that orchestrates all services
|
||||
│ ├── Chart.yaml
|
||||
│ ├── values.yaml # Configuration values for different environments
|
||||
│ └── Chart.lock
|
||||
└── apps-charts/ # Individual service charts
|
||||
├── jan-api-gateway/ # API Gateway service chart
|
||||
└── jan-inference-model/ # Inference Model service chart
|
||||
```
|
||||
|
||||
**Chart Features:**
|
||||
- **Umbrella Chart**: Main deployment chart that orchestrates all services
|
||||
- **Service Charts**: Individual charts for each service (API Gateway, Inference Model)
|
||||
- **Values Files**: Configuration files for different environments
|
||||
|
||||
## Security Architecture
|
||||
|
||||
### Authentication Methods
|
||||
- **JWT Tokens**: HMAC-SHA256 signed tokens for API access
|
||||
- **OAuth2**: Google OAuth2 integration for user login
|
||||
- **API Keys**: HMAC-SHA256 signed keys for service access
|
||||
|
||||
### Network Security
|
||||
- **Internal Communication**: Services communicate over Kubernetes cluster network
|
||||
- **External Access**: Only API gateway exposed via port forwarding or ingress
|
||||
- **Database Access**: PostgreSQL accessible only within cluster
|
||||
|
||||
### Data Security
|
||||
- **Secrets Management**: Kubernetes secrets for sensitive configuration
|
||||
- **Environment Variables**: Non-sensitive config via environment variables
|
||||
- **Database Encryption**: Standard PostgreSQL encryption at rest
|
||||
|
||||
Production deployments should implement additional security measures including TLS termination, network policies, and secret rotation.
|
||||
|
||||
## Monitoring & Observability
|
||||
|
||||
### Health Monitoring
|
||||
- **Health Check Endpoints**: Available on all services
|
||||
- **Model Health Monitoring**: Automated health checks for inference models
|
||||
- **Database Health**: Connection monitoring and replica status
|
||||
|
||||
### Performance Profiling
|
||||
- **pprof Endpoints**: Available on port 6060 for performance analysis
|
||||
- **Grafana Pyroscope**: Continuous profiling integration
|
||||
- **Request Tracing**: Unique request IDs for end-to-end tracing
|
||||
|
||||
### Logging
|
||||
- **Structured Logging**: JSON-formatted logs across all services
|
||||
- **Request/Response Logging**: Complete request lifecycle tracking
|
||||
- **Error Tracking**: Unique error codes for debugging
|
||||
|
||||
### Database Monitoring
|
||||
- **Read/Write Replica Support**: Automatic load balancing
|
||||
- **Connection Pooling**: Optimized database connections
|
||||
- **Migration Tracking**: Automatic schema migration monitoring
|
||||
- **Transaction Monitoring**: Automatic rollback on errors
|
||||
|
||||
## Scalability Considerations
|
||||
|
||||
**Current Limitations:**
|
||||
- Single replica deployments
|
||||
- No horizontal pod autoscaling
|
||||
- Local storage for database
|
||||
|
||||
**Future Enhancements:**
|
||||
- Multi-replica API gateway with load balancing
|
||||
- Horizontal pod autoscaling based on CPU/memory
|
||||
- External database with clustering
|
||||
- Redis caching layer
|
||||
- Message queue for async processing
|
||||
|
||||
## Project Structure
|
||||
|
||||
```
|
||||
jan-server/
|
||||
├── apps/ # Application services
|
||||
│ ├── jan-api-gateway/ # Main API gateway service
|
||||
│ │ ├── application/ # Go application code
|
||||
│ │ ├── docker/ # Docker configuration
|
||||
│ │ └── README.md # Service-specific documentation
|
||||
│ └── jan-inference-model/ # AI model inference service
|
||||
│ ├── application/ # Python application code
|
||||
│ └── Dockerfile # Container configuration
|
||||
├── charts/ # Helm charts
|
||||
│ ├── apps-charts/ # Individual service charts
|
||||
│ └── umbrella-chart/ # Main deployment chart
|
||||
├── scripts/ # Deployment and utility scripts
|
||||
└── README.md # Main documentation
|
||||
```
|
||||
|
||||
## Development Architecture
|
||||
|
||||
### Building Services
|
||||
|
||||
```bash
|
||||
# Build API Gateway
|
||||
docker build -t jan-api-gateway:latest ./apps/jan-api-gateway
|
||||
|
||||
# Build Inference Model
|
||||
docker build -t jan-inference-model:latest ./apps/jan-inference-model
|
||||
```
|
||||
|
||||
### Database Migrations
|
||||
|
||||
The system uses Atlas for database migrations:
|
||||
|
||||
```bash
|
||||
# Generate migration files
|
||||
go run ./apps/jan-api-gateway/application/cmd/codegen/dbmigration
|
||||
|
||||
# Apply migrations
|
||||
atlas migrate apply --url "your-database-url"
|
||||
```
|
||||
|
||||
### Code Generation
|
||||
- **Swagger**: API documentation generated from Go annotations
|
||||
- **Wire**: Dependency injection code generated from providers
|
||||
- **GORM Gen**: Database model generation from schema
|
||||
|
||||
### Build Process
|
||||
1. **API Gateway**: Multi-stage Docker build with Go compilation
|
||||
2. **Inference Model**: Base VLLM image with model download
|
||||
3. **Helm Charts**: Dependency management and templating
|
||||
4. **Documentation**: Auto-generation during development
|
||||
|
||||
### Local Development
|
||||
- **Hot Reload**: Source code changes reflected without full rebuild
|
||||
- **Database Migrations**: Automated schema updates
|
||||
- **API Testing**: Swagger UI for interactive testing
|
||||
- **Logging**: Structured logging with configurable levels
|
||||
@ -1,349 +0,0 @@
|
||||
---
|
||||
title: Configuration
|
||||
description: Configure Jan Server environment variables, authentication, external integrations, and deployment settings.
|
||||
---
|
||||
|
||||
## Configuration
|
||||
|
||||
### Environment Variables
|
||||
|
||||
The system is configured through environment variables defined in the Helm values file. Key configuration areas include:
|
||||
|
||||
#### Jan API Gateway Configuration
|
||||
- **Database Connection**: PostgreSQL connection strings for read/write replicas
|
||||
- **Authentication**: JWT secrets and Google OAuth2 credentials
|
||||
- **API Keys**: Encryption secrets for API key management
|
||||
- **External Services**: Serper API key for web search functionality
|
||||
- **Model Integration**: Jan Inference Model service URL
|
||||
|
||||
#### Security Configuration
|
||||
- **JWT_SECRET**: HMAC-SHA-256 secret for JWT token signing
|
||||
- **APIKEY_SECRET**: HMAC-SHA-256 secret for API key encryption
|
||||
- **Database Credentials**: PostgreSQL username, password, and database name
|
||||
|
||||
#### External Service Integration
|
||||
- **SERPER_API_KEY**: API key for web search functionality
|
||||
- **Google OAuth2**: Client ID, secret, and redirect URL for authentication
|
||||
- **Model Service**: URL for Jan Inference Model service communication
|
||||
|
||||
### Complete Environment Variables Reference
|
||||
|
||||
| Variable | Description | Default |
|
||||
|----------|-------------|---------|
|
||||
| `DB_POSTGRESQL_WRITE_DSN` | Primary database connection | `postgres://jan_user:jan_password@localhost:5432/jan_api_gateway?sslmode=disable` |
|
||||
| `DB_POSTGRESQL_READ1_DSN` | Read replica database connection | Same as write DSN |
|
||||
| `JWT_SECRET` | JWT token signing secret | `your-super-secret-jwt-key-change-in-production` |
|
||||
| `APIKEY_SECRET` | API key encryption secret | `your-api-key-secret-change-in-production` |
|
||||
| `JAN_INFERENCE_MODEL_URL` | Jan inference service URL | `http://localhost:8000` |
|
||||
| `SERPER_API_KEY` | Serper API key for web search | `your-serper-api-key` |
|
||||
| `OAUTH2_GOOGLE_CLIENT_ID` | Google OAuth2 client ID | `your-google-client-id` |
|
||||
| `OAUTH2_GOOGLE_CLIENT_SECRET` | Google OAuth2 client secret | `your-google-client-secret` |
|
||||
| `OAUTH2_GOOGLE_REDIRECT_URL` | Google OAuth2 redirect URL | `http://localhost:8080/auth/google/callback` |
|
||||
| `ALLOWED_CORS_HOSTS` | Value of allowed CORS hosts, separated by commas, supporting prefix wildcards with '*'. | `http://localhost:8080,*jan.ai` |
|
||||
| `SMTP_HOST` | SMTP server host for email notifications | `smtp.gmail.com` |
|
||||
| `SMTP_PORT` | SMTP server port | `587` |
|
||||
| `SMTP_USERNAME` | SMTP username | `your-smtp-username` |
|
||||
| `SMTP_PASSWORD` | SMTP password | `your-smtp-password` |
|
||||
| `SMTP_SENDER_EMAIL` | Default sender email address | `noreply@yourdomain.com` |
|
||||
| `INVITE_REDIRECT_URL` | Redirect URL for invitation acceptance | `http://localhost:8080/invite/accept` |
|
||||
|
||||
### Helm Configuration
|
||||
|
||||
The system uses Helm charts for deployment configuration:
|
||||
|
||||
- **Umbrella Chart**: Main deployment chart that orchestrates all services
|
||||
- **Service Charts**: Individual charts for each service (API Gateway, Inference Model)
|
||||
- **Values Files**: Configuration files for different environments
|
||||
|
||||
### Updating Values
|
||||
|
||||
Edit the configuration in `charts/umbrella-chart/values.yaml`:
|
||||
|
||||
```yaml
|
||||
jan-api-gateway:
|
||||
env:
|
||||
- name: SERPER_API_KEY
|
||||
value: your_serper_api_key
|
||||
- name: OAUTH2_GOOGLE_CLIENT_ID
|
||||
value: your_google_client_id
|
||||
- name: OAUTH2_GOOGLE_CLIENT_SECRET
|
||||
value: your_google_client_secret
|
||||
- name: JWT_SECRET
|
||||
value: your-jwt-secret-key
|
||||
- name: APIKEY_SECRET
|
||||
value: your-api-key-secret
|
||||
- name: SMTP_HOST
|
||||
value: smtp.gmail.com
|
||||
- name: SMTP_USERNAME
|
||||
value: your-smtp-username
|
||||
- name: SMTP_PASSWORD
|
||||
value: your-smtp-password
|
||||
```
|
||||
|
||||
### Applying Changes
|
||||
|
||||
After modifying values, redeploy the application:
|
||||
|
||||
```bash
|
||||
# Update Helm dependencies
|
||||
helm dependency update ./charts/umbrella-chart
|
||||
|
||||
# Deploy to production
|
||||
helm install jan-server ./charts/umbrella-chart
|
||||
|
||||
# Upgrade deployment
|
||||
helm upgrade jan-server ./charts/umbrella-chart
|
||||
|
||||
# Uninstall
|
||||
helm uninstall jan-server
|
||||
```
|
||||
|
||||
## Authentication Setup
|
||||
|
||||
### JWT Tokens
|
||||
|
||||
Generate a secure JWT signing key:
|
||||
|
||||
```bash
|
||||
# Generate 256-bit key for HMAC-SHA256
|
||||
openssl rand -base64 32
|
||||
```
|
||||
|
||||
Update the `JWT_SECRET` value in your Helm configuration.
|
||||
|
||||
### API Keys
|
||||
|
||||
Generate a secure API key signing secret:
|
||||
|
||||
```bash
|
||||
# Generate 256-bit key for HMAC-SHA256
|
||||
openssl rand -base64 32
|
||||
```
|
||||
|
||||
Update the `APIKEY_SECRET` value in your Helm configuration.
|
||||
|
||||
### Google OAuth2
|
||||
|
||||
1. **Create Google Cloud Project**
|
||||
- Go to [Google Cloud Console](https://console.cloud.google.com)
|
||||
- Create a new project or select existing
|
||||
|
||||
2. **Enable OAuth2**
|
||||
- Navigate to "APIs & Services" > "Credentials"
|
||||
- Create OAuth2 client ID credentials
|
||||
- Set application type to "Web application"
|
||||
|
||||
3. **Configure Redirect URI**
|
||||
```
|
||||
http://localhost:8080/auth/google/callback
|
||||
```
|
||||
|
||||
4. **Update Configuration**
|
||||
- Set `OAUTH2_GOOGLE_CLIENT_ID` to your client ID
|
||||
- Set `OAUTH2_GOOGLE_CLIENT_SECRET` to your client secret
|
||||
- Set `OAUTH2_GOOGLE_REDIRECT_URL` to your callback URL
|
||||
|
||||
## External Integrations
|
||||
|
||||
### Serper API
|
||||
|
||||
Jan Server integrates with Serper for web search capabilities.
|
||||
|
||||
1. **Get API Key**
|
||||
- Register at [serper.dev](https://serper.dev)
|
||||
- Generate API key from dashboard
|
||||
|
||||
2. **Configure**
|
||||
- Set `SERPER_API_KEY` in Helm values
|
||||
- Redeploy the application
|
||||
|
||||
### Adding New Integrations
|
||||
|
||||
To add new external API integrations:
|
||||
|
||||
1. **Update Helm Values**
|
||||
```yaml
|
||||
jan-api-gateway:
|
||||
env:
|
||||
- name: YOUR_API_KEY
|
||||
value: your_api_key_value
|
||||
```
|
||||
|
||||
2. **Update Go Configuration**
|
||||
|
||||
Add to `config/environment_variables/env.go`:
|
||||
```go
|
||||
YourAPIKey string `env:"YOUR_API_KEY"`
|
||||
```
|
||||
|
||||
3. **Redeploy**
|
||||
```bash
|
||||
helm upgrade jan-server ./charts/umbrella-chart
|
||||
```
|
||||
|
||||
## Database Configuration
|
||||
|
||||
### Connection Settings
|
||||
|
||||
The default PostgreSQL configuration uses:
|
||||
- **Host**: `jan-server-postgresql` (Kubernetes service name)
|
||||
- **Database**: `jan`
|
||||
- **User**: `jan-user`
|
||||
- **Password**: `jan-password`
|
||||
- **Port**: `5432`
|
||||
- **SSL**: Disabled (development only)
|
||||
|
||||
### Production Database
|
||||
|
||||
For production deployments:
|
||||
|
||||
1. **External Database**
|
||||
- Use managed PostgreSQL service (AWS RDS, Google Cloud SQL)
|
||||
- Update DSN variables with external connection details
|
||||
|
||||
2. **SSL/TLS**
|
||||
- Enable `sslmode=require` in connection strings
|
||||
- Configure certificate validation
|
||||
|
||||
3. **Connection Pooling**
|
||||
- Consider using connection pooler (PgBouncer, pgpool-II)
|
||||
- Configure appropriate pool sizes
|
||||
|
||||
## Model Configuration
|
||||
|
||||
The inference model service is configured via Docker CMD parameters:
|
||||
|
||||
```dockerfile
|
||||
CMD ["--model", "/models/Jan-v1-4B", \
|
||||
"--served-model-name", "jan-v1-4b", \
|
||||
"--host", "0.0.0.0", \
|
||||
"--port", "8101", \
|
||||
"--max-num-batched-tokens", "1024", \
|
||||
"--enable-auto-tool-choice", \
|
||||
"--tool-call-parser", "hermes", \
|
||||
"--reasoning-parser", "qwen3"]
|
||||
```
|
||||
|
||||
### Model Parameters
|
||||
|
||||
| Parameter | Value | Description |
|
||||
|-----------|-------|-------------|
|
||||
| `--model` | `/models/Jan-v1-4B` | Path to model files |
|
||||
| `--served-model-name` | `jan-v1-4b` | API model identifier |
|
||||
| `--max-num-batched-tokens` | `1024` | Maximum tokens per batch |
|
||||
| `--tool-call-parser` | `hermes` | Tool calling format |
|
||||
| `--reasoning-parser` | `qwen3` | Reasoning output format |
|
||||
|
||||
Model configuration changes require rebuilding the inference Docker image. This will be configurable via environment variables in future releases.
|
||||
|
||||
## Resource Configuration
|
||||
|
||||
### Kubernetes Resources
|
||||
|
||||
Current deployments use default resource limits. For production:
|
||||
|
||||
```yaml
|
||||
jan-api-gateway:
|
||||
resources:
|
||||
requests:
|
||||
cpu: 100m
|
||||
memory: 128Mi
|
||||
limits:
|
||||
cpu: 500m
|
||||
memory: 512Mi
|
||||
|
||||
jan-inference-model:
|
||||
resources:
|
||||
requests:
|
||||
cpu: 1000m
|
||||
memory: 4Gi
|
||||
limits:
|
||||
cpu: 4000m
|
||||
memory: 8Gi
|
||||
```
|
||||
|
||||
### Storage
|
||||
|
||||
PostgreSQL uses default Kubernetes storage. For production:
|
||||
|
||||
```yaml
|
||||
postgresql:
|
||||
persistence:
|
||||
enabled: true
|
||||
size: 20Gi
|
||||
storageClass: fast-ssd
|
||||
```
|
||||
|
||||
## Monitoring & Observability
|
||||
|
||||
### Health Monitoring
|
||||
- **Health Check Endpoints**: Available on all services
|
||||
- **Model Health Monitoring**: Automated health checks for inference models
|
||||
- **Database Health**: Connection monitoring and replica status
|
||||
|
||||
### Performance Profiling
|
||||
- **pprof Endpoints**: Available on port 6060 for performance analysis
|
||||
- **Grafana Pyroscope**: Continuous profiling integration
|
||||
- **Request Tracing**: Unique request IDs for end-to-end tracing
|
||||
|
||||
### Logging
|
||||
- **Structured Logging**: JSON-formatted logs across all services
|
||||
- **Request/Response Logging**: Complete request lifecycle tracking
|
||||
- **Error Tracking**: Unique error codes for debugging
|
||||
|
||||
Configure logging levels via environment variables:
|
||||
|
||||
```yaml
|
||||
jan-api-gateway:
|
||||
env:
|
||||
- name: LOG_LEVEL
|
||||
value: info
|
||||
- name: LOG_FORMAT
|
||||
value: json
|
||||
```
|
||||
|
||||
Available log levels: `debug`, `info`, `warn`, `error`
|
||||
Available formats: `text`, `json`
|
||||
|
||||
## Security
|
||||
|
||||
### Authentication & Authorization
|
||||
- **JWT Tokens**: Secure token-based authentication
|
||||
- **Google OAuth2**: Social authentication integration
|
||||
- **API Key Management**: Scoped API keys for different access levels
|
||||
- **Multi-tenant Security**: Organization and project-level access control
|
||||
|
||||
### Data Protection
|
||||
- **Encrypted API Keys**: HMAC-SHA-256 encryption for sensitive data
|
||||
- **Secure Database Connections**: SSL-enabled database connections
|
||||
- **Environment Variable Security**: Secure handling of sensitive configuration
|
||||
|
||||
## Deployment
|
||||
|
||||
### Local Development
|
||||
```bash
|
||||
# Start local cluster
|
||||
minikube start
|
||||
eval $(minikube docker-env)
|
||||
|
||||
# Deploy services
|
||||
./scripts/run.sh
|
||||
|
||||
# Access services
|
||||
kubectl port-forward svc/jan-server-jan-api-gateway 8080:8080
|
||||
```
|
||||
|
||||
### Production Deployment
|
||||
```bash
|
||||
# Update Helm dependencies
|
||||
helm dependency update ./charts/umbrella-chart
|
||||
|
||||
# Deploy to production
|
||||
helm install jan-server ./charts/umbrella-chart
|
||||
|
||||
# Upgrade deployment
|
||||
helm upgrade jan-server ./charts/umbrella-chart
|
||||
|
||||
# Uninstall
|
||||
helm uninstall jan-server
|
||||
```
|
||||
@ -1,592 +0,0 @@
|
||||
---
|
||||
title: Development
|
||||
description: Development setup, workflow, and contribution guidelines for Jan Server.
|
||||
---
|
||||
## Core Domain Models
|
||||

|
||||
## Development Setup
|
||||
|
||||
### Prerequisites
|
||||
|
||||
- **Go**: 1.24.6 or later
|
||||
- **Docker & Docker Compose**: For containerization
|
||||
- **PostgreSQL**: Database (or use Docker)
|
||||
- **Atlas**: For database migrations (`brew install ariga/tap/atlas`)
|
||||
- **minikube**: Local Kubernetes development
|
||||
- **Helm**: Package management
|
||||
- **Make**: Build automation
|
||||
|
||||
### Local Development
|
||||
|
||||
1. **Clone and setup**:
|
||||
```bash
|
||||
git clone <repository-url>
|
||||
cd jan-api-gateway/application
|
||||
make setup
|
||||
go mod tidy
|
||||
```
|
||||
|
||||
2. **Start the server**:
|
||||
```bash
|
||||
go run ./cmd/server
|
||||
```
|
||||
|
||||
3. **Access the API**:
|
||||
- API Base URL: `http://localhost:8080`
|
||||
- Swagger UI: `http://localhost:8080/api/swagger/index.html`
|
||||
- Health Check: `http://localhost:8080/healthcheck`
|
||||
- Version Info: `http://localhost:8080/v1/version`
|
||||
- Profiling Endpoints: `http://localhost:6060/debug/pprof/`
|
||||
|
||||
### Initial Setup
|
||||
|
||||
1. **Clone Repository**
|
||||
```bash
|
||||
git clone https://github.com/menloresearch/jan-server
|
||||
cd jan-server
|
||||
```
|
||||
|
||||
2. **Setup API Gateway**
|
||||
```bash
|
||||
cd apps/jan-api-gateway/application
|
||||
make setup
|
||||
go mod tidy
|
||||
```
|
||||
|
||||
3. **Start the Server**
|
||||
```bash
|
||||
go run ./cmd/server
|
||||
```
|
||||
|
||||
4. **Access the API**
|
||||
- API Base URL: `http://localhost:8080`
|
||||
- Swagger UI: `http://localhost:8080/api/swagger/index.html`
|
||||
- Health Check: `http://localhost:8080/healthcheck`
|
||||
- Version Info: `http://localhost:8080/v1/version`
|
||||
- Profiling Endpoints: `http://localhost:6060/debug/pprof/`
|
||||
|
||||
### Environment Variables
|
||||
|
||||
The system is configured through environment variables. Key configuration areas include:
|
||||
|
||||
| Variable | Description | Default |
|
||||
|----------|-------------|---------|
|
||||
| `DB_POSTGRESQL_WRITE_DSN` | Primary database connection | `postgres://jan_user:jan_password@localhost:5432/jan_api_gateway?sslmode=disable` |
|
||||
| `DB_POSTGRESQL_READ1_DSN` | Read replica database connection | Same as write DSN |
|
||||
| `JWT_SECRET` | JWT token signing secret | `your-super-secret-jwt-key-change-in-production` |
|
||||
| `APIKEY_SECRET` | API key encryption secret | `your-api-key-secret-change-in-production` |
|
||||
| `JAN_INFERENCE_MODEL_URL` | Jan inference service URL | `http://localhost:8000` |
|
||||
| `SERPER_API_KEY` | Serper API key for web search | `your-serper-api-key` |
|
||||
| `OAUTH2_GOOGLE_CLIENT_ID` | Google OAuth2 client ID | `your-google-client-id` |
|
||||
| `OAUTH2_GOOGLE_CLIENT_SECRET` | Google OAuth2 client secret | `your-google-client-secret` |
|
||||
| `OAUTH2_GOOGLE_REDIRECT_URL` | Google OAuth2 redirect URL | `http://localhost:8080/auth/google/callback` |
|
||||
| `ALLOWED_CORS_HOSTS` | Allowed CORS hosts, separated by commas, supporting prefix wildcards with '*' | `http://localhost:8080,*jan.ai` |
|
||||
| `SMTP_HOST` | SMTP server host for email notifications | `smtp.gmail.com` |
|
||||
| `SMTP_PORT` | SMTP server port | `587` |
|
||||
| `SMTP_USERNAME` | SMTP username | `your-smtp-username` |
|
||||
| `SMTP_PASSWORD` | SMTP password | `your-smtp-password` |
|
||||
| `SMTP_SENDER_EMAIL` | Default sender email address | `noreply@yourdomain.com` |
|
||||
| `INVITE_REDIRECT_URL` | Redirect URL for invitation acceptance | `http://localhost:8080/invite/accept` |
|
||||
|
||||
3. **Generate Code**
|
||||
```bash
|
||||
make setup
|
||||
```
|
||||
|
||||
4. **Start Development Environment**
|
||||
```bash
|
||||
# From project root
|
||||
./scripts/run.sh
|
||||
```
|
||||
|
||||
## API Gateway Development
|
||||
|
||||
### Project Structure
|
||||
|
||||
```
|
||||
jan-api-gateway/
|
||||
├── application/ # Main Go application
|
||||
│ ├── app/
|
||||
│ │ ├── cmd/server/ # Server entry point
|
||||
│ │ ├── domain/ # Business logic and entities
|
||||
│ │ ├── infrastructure/ # Database and external services
|
||||
│ │ ├── interfaces/ # HTTP handlers and routes
|
||||
│ │ └── utils/ # Utilities and helpers
|
||||
│ ├── config/ # Configuration management
|
||||
│ ├── docs/ # Swagger documentation
|
||||
│ └── Makefile # Build automation
|
||||
├── docker/ # Docker configuration
|
||||
└── LOCAL_DEV_SETUP.md # Detailed development setup
|
||||
```
|
||||
|
||||
### Database Migrations
|
||||
|
||||
The project uses Atlas for database migrations. To generate and apply migrations:
|
||||
|
||||
1. **Setup migration database**:
|
||||
```sql
|
||||
CREATE ROLE migration WITH LOGIN PASSWORD 'migration';
|
||||
ALTER ROLE migration WITH SUPERUSER;
|
||||
CREATE DATABASE migration WITH OWNER = migration;
|
||||
```
|
||||
|
||||
2. **Generate migration files**:
|
||||
```bash
|
||||
# Generate schema files
|
||||
go run ./cmd/codegen/dbmigration
|
||||
|
||||
# Generate diff SQL
|
||||
atlas schema diff --dev-url "postgres://migration:migration@localhost:5432/migration?sslmode=disable" \
|
||||
--from file://tmp/release.hcl --to file://tmp/main.hcl > tmp/diff.sql
|
||||
```
|
||||
|
||||
3. **Apply migrations**:
|
||||
```bash
|
||||
# Auto-migration on startup (development)
|
||||
go run ./cmd/server
|
||||
|
||||
# Manual migration (production)
|
||||
atlas migrate apply --url "your-production-db-url"
|
||||
```
|
||||
|
||||
### Build Commands
|
||||
|
||||
```bash
|
||||
# Install development dependencies
|
||||
make install
|
||||
|
||||
# Generate API documentation
|
||||
make doc
|
||||
|
||||
# Generate dependency injection code
|
||||
make wire
|
||||
|
||||
# Complete setup (doc + wire)
|
||||
make setup
|
||||
|
||||
# Build application
|
||||
go build -o jan-api-gateway ./cmd/server
|
||||
```
|
||||
|
||||
### Code Generation
|
||||
|
||||
Jan Server uses code generation for several components:
|
||||
|
||||
**Swagger Documentation:**
|
||||
```bash
|
||||
# Generates docs/swagger.json and docs/swagger.yaml
|
||||
swag init --parseDependency -g cmd/server/server.go -o docs
|
||||
```
|
||||
|
||||
**Dependency Injection:**
|
||||
```bash
|
||||
# Generates wire_gen.go from wire.go providers
|
||||
wire ./cmd/server
|
||||
```
|
||||
|
||||
**Database Models:**
|
||||
```bash
|
||||
# Generate GORM models (when schema changes)
|
||||
go run cmd/codegen/gorm/gorm.go
|
||||
```
|
||||
|
||||
## Key Features Implementation
|
||||
|
||||
### Streaming with Server-Sent Events
|
||||
The chat completion endpoints implement real-time streaming using Server-Sent Events (SSE) with chunked transfer encoding, providing low-latency responses for AI model interactions. The system supports both content and reasoning content streaming with proper buffering and event sequencing.
|
||||
|
||||
### Multi-Tenant Architecture
|
||||
Organizations and projects provide hierarchical access control with fine-grained permissions and resource isolation. API keys can be scoped to organization or project levels with different types (admin, project, organization, service, ephemeral) for various use cases.
|
||||
|
||||
### OpenAI Compatibility
|
||||
Full compatibility with OpenAI's chat completion API, including streaming, function calls, tool usage, and all standard parameters (temperature, max_tokens, etc.). The system also supports reasoning content and multimodal inputs.
|
||||
|
||||
### Model Context Protocol (MCP)
|
||||
Comprehensive MCP implementation supporting tools, prompts, and resources with JSON-RPC 2.0 protocol. Includes Serper API integration for web search capabilities and webpage fetching functionality.
|
||||
|
||||
### Database Architecture
|
||||
- Read/Write replica support with automatic load balancing using GORM dbresolver
|
||||
- Transaction management with automatic rollback on errors
|
||||
- Generated query interfaces using GORM Gen for type safety
|
||||
- Automatic schema migrations with Atlas integration
|
||||
- Support for complex data types including JSON fields and relationships
|
||||
|
||||
### Monitoring & Observability
|
||||
- Built-in pprof endpoints for performance profiling on port 6060
|
||||
- Grafana Pyroscope integration for continuous profiling
|
||||
- Structured logging with unique request IDs and comprehensive request/response tracking
|
||||
- Automated health checks for inference model endpoints with cron-based monitoring
|
||||
- Model registry with dynamic service discovery and health status tracking
|
||||
|
||||
### Local Development
|
||||
|
||||
#### Running API Gateway Locally
|
||||
|
||||
```bash
|
||||
cd apps/jan-api-gateway/application
|
||||
|
||||
# Set environment variables
|
||||
export JAN_INFERENCE_MODEL_URL=http://localhost:8101
|
||||
export JWT_SECRET=your-jwt-secret
|
||||
export DB_POSTGRESQL_WRITE_DSN="host=localhost user=jan-user password=jan-password dbname=jan port=5432 sslmode=disable"
|
||||
|
||||
# Run the server
|
||||
go run ./cmd/server
|
||||
```
|
||||
|
||||
#### Database Setup
|
||||
|
||||
For local development, you can run PostgreSQL directly:
|
||||
|
||||
```bash
|
||||
# Using Docker
|
||||
docker run -d \
|
||||
--name jan-postgres \
|
||||
-e POSTGRES_DB=jan \
|
||||
-e POSTGRES_USER=jan-user \
|
||||
-e POSTGRES_PASSWORD=jan-password \
|
||||
-p 5432:5432 \
|
||||
postgres:14
|
||||
```
|
||||
|
||||
## Testing
|
||||
|
||||
### Running Tests
|
||||
|
||||
```bash
|
||||
# Run all tests
|
||||
go test ./...
|
||||
|
||||
# Run tests with coverage
|
||||
go test -cover ./...
|
||||
|
||||
# Run specific test package
|
||||
go test ./app/service/...
|
||||
```
|
||||
|
||||
### Test Structure
|
||||
|
||||
```
|
||||
app/
|
||||
├── service/
|
||||
│ ├── auth_service.go
|
||||
│ ├── auth_service_test.go
|
||||
│ ├── conversation_service.go
|
||||
│ └── conversation_service_test.go
|
||||
└── handler/
|
||||
├── auth_handler.go
|
||||
├── auth_handler_test.go
|
||||
├── chat_handler.go
|
||||
└── chat_handler_test.go
|
||||
```
|
||||
|
||||
### Writing Tests
|
||||
|
||||
Example service test:
|
||||
|
||||
```go
|
||||
func TestAuthService_ValidateToken(t *testing.T) {
|
||||
// Setup
|
||||
service := NewAuthService(mockRepo, mockConfig)
|
||||
|
||||
// Test cases
|
||||
tests := []struct {
|
||||
name string
|
||||
token string
|
||||
expectValid bool
|
||||
expectError bool
|
||||
}{
|
||||
{"valid token", "valid.jwt.token", true, false},
|
||||
{"invalid token", "invalid.token", false, true},
|
||||
}
|
||||
|
||||
for _, tt := range tests {
|
||||
t.Run(tt.name, func(t *testing.T) {
|
||||
valid, err := service.ValidateToken(tt.token)
|
||||
assert.Equal(t, tt.expectValid, valid)
|
||||
assert.Equal(t, tt.expectError, err != nil)
|
||||
})
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
## Docker Development
|
||||
|
||||
### Building Images
|
||||
|
||||
```bash
|
||||
# Build API gateway
|
||||
docker build -t jan-api-gateway:dev ./apps/jan-api-gateway
|
||||
|
||||
# Build inference model
|
||||
docker build -t jan-inference-model:dev ./apps/jan-inference-model
|
||||
```
|
||||
|
||||
### Development Compose
|
||||
|
||||
For local development without Kubernetes:
|
||||
|
||||
```yaml
|
||||
# docker-compose.dev.yml
|
||||
version: '3.8'
|
||||
services:
|
||||
postgres:
|
||||
image: postgres:14
|
||||
environment:
|
||||
POSTGRES_DB: jan
|
||||
POSTGRES_USER: jan-user
|
||||
POSTGRES_PASSWORD: jan-password
|
||||
ports:
|
||||
- "5432:5432"
|
||||
|
||||
api-gateway:
|
||||
build: ./apps/jan-api-gateway
|
||||
ports:
|
||||
- "8080:8080"
|
||||
environment:
|
||||
- JAN_INFERENCE_MODEL_URL=http://inference-model:8101
|
||||
- DB_POSTGRESQL_WRITE_DSN=host=postgres user=jan-user password=jan-password dbname=jan port=5432 sslmode=disable
|
||||
depends_on:
|
||||
- postgres
|
||||
|
||||
inference-model:
|
||||
build: ./apps/jan-inference-model
|
||||
ports:
|
||||
- "8101:8101"
|
||||
```
|
||||
|
||||
## Debugging
|
||||
|
||||
### Go Debugging
|
||||
|
||||
For VS Code debugging, add to `.vscode/launch.json`:
|
||||
|
||||
```json
|
||||
{
|
||||
"version": "0.2.0",
|
||||
"configurations": [
|
||||
{
|
||||
"name": "Launch Jan API Gateway",
|
||||
"type": "go",
|
||||
"request": "launch",
|
||||
"mode": "auto",
|
||||
"program": "${workspaceFolder}/apps/jan-api-gateway/application/cmd/server",
|
||||
"env": {
|
||||
"JAN_INFERENCE_MODEL_URL": "http://localhost:8101",
|
||||
"JWT_SECRET": "development-secret"
|
||||
}
|
||||
}
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
### Application Logs
|
||||
|
||||
```bash
|
||||
# View API gateway logs
|
||||
kubectl logs deployment/jan-server-jan-api-gateway -f
|
||||
|
||||
# View inference model logs
|
||||
kubectl logs deployment/jan-server-jan-inference-model -f
|
||||
|
||||
# View PostgreSQL logs
|
||||
kubectl logs statefulset/jan-server-postgresql -f
|
||||
```
|
||||
|
||||
### Log Levels
|
||||
|
||||
Set log level via environment variable:
|
||||
|
||||
```bash
|
||||
export LOG_LEVEL=debug # debug, info, warn, error
|
||||
```
|
||||
|
||||
## Code Style and Standards
|
||||
|
||||
### Go Standards
|
||||
|
||||
- Follow [Go Code Review Comments](https://go.dev/wiki/CodeReviewComments)
|
||||
- Use `gofmt` for formatting
|
||||
- Run `go vet` for static analysis
|
||||
- Use meaningful variable and function names
|
||||
|
||||
### API Standards
|
||||
|
||||
- RESTful endpoint design
|
||||
- OpenAPI/Swagger annotations for all endpoints
|
||||
- Consistent error response format
|
||||
- Proper HTTP status codes
|
||||
|
||||
### Git Workflow
|
||||
|
||||
```bash
|
||||
# Create feature branch
|
||||
git checkout -b feature/your-feature-name
|
||||
|
||||
# Make changes and commit
|
||||
git add .
|
||||
git commit -m "feat: add new authentication endpoint"
|
||||
|
||||
# Push and create PR
|
||||
git push origin feature/your-feature-name
|
||||
```
|
||||
|
||||
### Commit Message Format
|
||||
|
||||
Follow conventional commits:
|
||||
|
||||
```
|
||||
feat: add new feature
|
||||
fix: resolve bug in authentication
|
||||
docs: update API documentation
|
||||
test: add unit tests for service layer
|
||||
refactor: improve error handling
|
||||
```
|
||||
|
||||
## Performance Testing
|
||||
|
||||
### Load Testing
|
||||
|
||||
Use [k6](https://k6.io) for API load testing:
|
||||
|
||||
```javascript
|
||||
// load-test.js
|
||||
import http from 'k6/http';
|
||||
|
||||
export default function () {
|
||||
const response = http.post('http://localhost:8080/api/v1/chat/completions', {
|
||||
model: 'jan-v1-4b',
|
||||
messages: [
|
||||
{ role: 'user', content: 'Hello!' }
|
||||
]
|
||||
}, {
|
||||
headers: {
|
||||
'Content-Type': 'application/json',
|
||||
'Authorization': 'Bearer your-token'
|
||||
}
|
||||
});
|
||||
|
||||
check(response, {
|
||||
'status is 200': (r) => r.status === 200,
|
||||
'response time < 5000ms': (r) => r.timings.duration < 5000,
|
||||
});
|
||||
}
|
||||
```
|
||||
|
||||
Run load test:
|
||||
```bash
|
||||
k6 run --vus 10 --duration 30s load-test.js
|
||||
```
|
||||
|
||||
### Memory Profiling
|
||||
|
||||
Enable Go profiling endpoints:
|
||||
|
||||
```go
|
||||
import _ "net/http/pprof"
|
||||
|
||||
// In main.go
|
||||
go func() {
|
||||
log.Println(http.ListenAndServe("localhost:6060", nil))
|
||||
}()
|
||||
```
|
||||
|
||||
Profile memory usage:
|
||||
```bash
|
||||
go tool pprof http://localhost:6060/debug/pprof/heap
|
||||
```
|
||||
|
||||
## Documentation
|
||||
|
||||
- **API Documentation**: Available at `/api/swagger/index.html` when running locally
|
||||
- **OpenAI-Style Documentation**: Professional API reference documentation with OpenAI-style layout
|
||||
- **Development Setup**: See [LOCAL_DEV_SETUP.md](LOCAL_DEV_SETUP.md) for detailed VS Code/Cursor setup
|
||||
- **Architecture**: See the mermaid diagram above for system architecture
|
||||
|
||||
### API Structure Overview
|
||||
|
||||
The API is organized into the following main groups:
|
||||
|
||||
1. **Authentication API** - User authentication and authorization
|
||||
2. **Chat Completions API** - Chat completions, models, and MCP functionality
|
||||
3. **Conversation-aware Chat API** - Conversation-based chat completions
|
||||
4. **Conversations API** - Conversation management and items
|
||||
5. **Responses API** - Response tracking and management
|
||||
6. **Administration API** - Organization and project management
|
||||
7. **Server API** - System information and health checks
|
||||
|
||||
### Swagger Documentation
|
||||
|
||||
The API documentation is automatically generated from code annotations and includes:
|
||||
- Interactive API explorer
|
||||
- Request/response examples
|
||||
- Authentication requirements
|
||||
- Error code documentation
|
||||
- Model schemas and validation rules
|
||||
|
||||
## Contributing
|
||||
|
||||
### Pull Request Process
|
||||
|
||||
1. **Fork the repository**
|
||||
2. **Create feature branch** from `main`
|
||||
3. **Make changes** following code standards
|
||||
4. **Add tests** for new functionality
|
||||
5. **Update documentation** if needed
|
||||
6. **Submit pull request** with clear description
|
||||
|
||||
### Code Review Checklist
|
||||
|
||||
- [ ] Code follows Go standards
|
||||
- [ ] Tests added for new features
|
||||
- [ ] Documentation updated
|
||||
- [ ] API endpoints have Swagger annotations
|
||||
- [ ] No breaking changes without version bump
|
||||
- [ ] Security considerations addressed
|
||||
|
||||
### Issues and Bug Reports
|
||||
|
||||
When reporting bugs, include:
|
||||
|
||||
- **Environment**: OS, Go version, minikube version
|
||||
- **Steps to reproduce**: Clear, minimal reproduction steps
|
||||
- **Expected behavior**: What should happen
|
||||
- **Actual behavior**: What actually happens
|
||||
- **Logs**: Relevant error messages or logs
|
||||
|
||||
For security issues, please report privately to the maintainers instead of creating public issues.
|
||||
|
||||
## Release Process
|
||||
|
||||
### Version Management
|
||||
|
||||
Jan Server uses semantic versioning (semver):
|
||||
|
||||
- **Major**: Breaking changes
|
||||
- **Minor**: New features, backward compatible
|
||||
- **Patch**: Bug fixes, backward compatible
|
||||
|
||||
### Building Releases
|
||||
|
||||
```bash
|
||||
# Tag release
|
||||
git tag -a v1.2.3 -m "Release v1.2.3"
|
||||
|
||||
# Build release images
|
||||
docker build -t jan-api-gateway:v1.2.3 ./apps/jan-api-gateway
|
||||
docker build -t jan-inference-model:v1.2.3 ./apps/jan-inference-model
|
||||
|
||||
# Push tags
|
||||
git push origin v1.2.3
|
||||
```
|
||||
|
||||
### Deployment
|
||||
|
||||
Production deployments follow the same Helm chart structure:
|
||||
|
||||
```bash
|
||||
# Deploy specific version
|
||||
helm install jan-server ./charts/umbrella-chart \
|
||||
--set jan-api-gateway.image.tag=v1.2.3 \
|
||||
--set jan-inference-model.image.tag=v1.2.3
|
||||
```
|
||||
@ -1,12 +0,0 @@
|
||||
import { useRouter } from 'next/router'
|
||||
import { useEffect } from 'react'
|
||||
|
||||
export default function ServerIndex() {
|
||||
const router = useRouter()
|
||||
|
||||
useEffect(() => {
|
||||
router.replace('/docs/server/overview')
|
||||
}, [router])
|
||||
|
||||
return null
|
||||
}
|
||||
@ -1,254 +0,0 @@
|
||||
---
|
||||
title: Installation
|
||||
description: Install and deploy Jan Server on Kubernetes using minikube and Helm with comprehensive setup instructions.
|
||||
---
|
||||
|
||||
## Prerequisites
|
||||
|
||||
Before setting up Jan Server, ensure you have the following components installed:
|
||||
|
||||
### Required Components
|
||||
|
||||
> **Important**: Windows and macOS users can only run mock servers for development. Real LLM model inference with vLLM is only supported on Linux systems with NVIDIA GPUs.
|
||||
|
||||
1. **Docker Desktop**
|
||||
- **Windows**: Download from [Docker Desktop for Windows](https://docs.docker.com/desktop/install/windows-install/)
|
||||
- **macOS**: Download from [Docker Desktop for Mac](https://docs.docker.com/desktop/install/mac-install/)
|
||||
- **Linux**: Follow [Docker Engine installation guide](https://docs.docker.com/engine/install/)
|
||||
|
||||
2. **Minikube**
|
||||
- **Windows**: `choco install minikube` or download from [minikube releases](https://github.com/kubernetes/minikube/releases)
|
||||
- **macOS**: `brew install minikube` or download from [minikube releases](https://github.com/kubernetes/minikube/releases)
|
||||
- **Linux**: `curl -LO https://storage.googleapis.com/minikube/releases/latest/minikube-linux-amd64 && sudo install minikube-linux-amd64 /usr/local/bin/minikube`
|
||||
|
||||
3. **Helm**
|
||||
- **Windows**: `choco install kubernetes-helm` or download from [Helm releases](https://github.com/helm/helm/releases)
|
||||
- **macOS**: `brew install helm` or download from [Helm releases](https://github.com/helm/helm/releases)
|
||||
- **Linux**: `curl https://raw.githubusercontent.com/helm/helm/main/scripts/get-helm-3 | bash`
|
||||
|
||||
4. **kubectl**
|
||||
- **Windows**: `choco install kubernetes-cli` or download from [kubectl releases](https://github.com/kubernetes/kubectl/releases)
|
||||
- **macOS**: `brew install kubectl` or download from [kubectl releases](https://github.com/kubernetes/kubectl/releases)
|
||||
- **Linux**: `curl -LO "https://dl.k8s.io/release/$(curl -L -s https://dl.k8s.io/release/stable.txt)/bin/linux/amd64/kubectl" && sudo install kubectl /usr/local/bin/kubectl`
|
||||
|
||||
### Optional: NVIDIA GPU Support (for Real LLM Models)
|
||||
If you plan to run real LLM models (not mock servers) and have an NVIDIA GPU:
|
||||
|
||||
1. **Install NVIDIA Container Toolkit**: Follow the [official NVIDIA Container Toolkit installation guide](https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/latest/install-guide.html)
|
||||
|
||||
2. **Configure Minikube for GPU support**: Follow the [official minikube GPU tutorial](https://minikube.sigs.k8s.io/docs/tutorials/nvidia/) for complete setup instructions.
|
||||
|
||||
## Quick Start
|
||||
|
||||
### Local Development Setup
|
||||
|
||||
#### Option 1: Mock Server Setup (Recommended for Development)
|
||||
|
||||
1. **Start Minikube and configure Docker**:
|
||||
```bash
|
||||
minikube start
|
||||
eval $(minikube docker-env)
|
||||
```
|
||||
|
||||
2. **Build and deploy all services**:
|
||||
```bash
|
||||
./scripts/run.sh
|
||||
```
|
||||
|
||||
3. **Access the services**:
|
||||
- **API Gateway**: http://localhost:8080
|
||||
- **Swagger UI**: http://localhost:8080/api/swagger/index.html
|
||||
- **Health Check**: http://localhost:8080/healthcheck
|
||||
- **Version Info**: http://localhost:8080/v1/version
|
||||
|
||||
#### Option 2: Real LLM Setup (Requires NVIDIA GPU)
|
||||
|
||||
1. **Start Minikube with GPU support**:
|
||||
```bash
|
||||
minikube start --gpus all
|
||||
eval $(minikube docker-env)
|
||||
```
|
||||
|
||||
2. **Configure GPU memory utilization** (if you have limited GPU memory):
|
||||
|
||||
GPU memory utilization is configured in the vLLM Dockerfile. See the [vLLM CLI documentation](https://docs.vllm.ai/en/latest/cli/serve.html) for all available arguments.
|
||||
|
||||
To modify GPU memory utilization, edit the vLLM launch command in:
|
||||
- `apps/jan-inference-model/Dockerfile` (for Docker builds)
|
||||
- Helm chart values (for Kubernetes deployment)
|
||||
|
||||
3. **Build and deploy all services**:
|
||||
```bash
|
||||
# For GPU setup, modify run.sh to use GPU-enabled minikube
|
||||
# Edit scripts/run.sh and change "minikube start" to "minikube start --gpus all"
|
||||
./scripts/run.sh
|
||||
```
|
||||
|
||||
### Production Deployment
|
||||
|
||||
For production deployments, modify the Helm values in `charts/umbrella-chart/values.yaml` and deploy using:
|
||||
|
||||
```bash
|
||||
helm install jan-server ./charts/umbrella-chart
|
||||
```
|
||||
|
||||
|
||||
## Manual Installation
|
||||
|
||||
### Build Docker Images
|
||||
|
||||
Build both required Docker images:
|
||||
|
||||
```bash
|
||||
# Build API Gateway
|
||||
docker build -t jan-api-gateway:latest ./apps/jan-api-gateway
|
||||
|
||||
# Build Inference Model
|
||||
docker build -t jan-inference-model:latest ./apps/jan-inference-model
|
||||
```
|
||||
|
||||
The inference model image downloads the Jan-v1-4B model from Hugging Face during build. This requires an internet connection and several GB of download.
|
||||
|
||||
### Deploy with Helm
|
||||
|
||||
Install the Helm chart:
|
||||
|
||||
```bash
|
||||
# Update Helm dependencies
|
||||
helm dependency update ./charts/umbrella-chart
|
||||
|
||||
# Install Jan Server
|
||||
helm install jan-server ./charts/umbrella-chart
|
||||
```
|
||||
|
||||
### Port Forwarding
|
||||
|
||||
Forward the API gateway port to access from your local machine:
|
||||
|
||||
```bash
|
||||
kubectl port-forward svc/jan-server-jan-api-gateway 8080:8080
|
||||
```
|
||||
|
||||
## Verify Installation
|
||||
|
||||
Check that all pods are running:
|
||||
|
||||
```bash
|
||||
kubectl get pods
|
||||
```
|
||||
|
||||
Expected output:
|
||||
```
|
||||
NAME READY STATUS RESTARTS
|
||||
jan-server-jan-api-gateway-xxx 1/1 Running 0
|
||||
jan-server-jan-inference-model-xxx 1/1 Running 0
|
||||
jan-server-postgresql-0 1/1 Running 0
|
||||
```
|
||||
|
||||
Test the API gateway:
|
||||
```bash
|
||||
curl http://localhost:8080/health
|
||||
```
|
||||
|
||||
## Uninstalling
|
||||
|
||||
To remove Jan Server:
|
||||
|
||||
```bash
|
||||
helm uninstall jan-server
|
||||
```
|
||||
|
||||
To stop minikube:
|
||||
|
||||
```bash
|
||||
minikube stop
|
||||
```
|
||||
|
||||
## Troubleshooting
|
||||
|
||||
### Common Issues and Solutions
|
||||
|
||||
### 1. LLM Pod Not Starting (Pending Status)
|
||||
|
||||
**Symptoms**: The `jan-server-jan-inference-model` pod stays in `Pending` status.
|
||||
|
||||
**Diagnosis Steps**:
|
||||
```bash
|
||||
# Check pod status
|
||||
kubectl get pods
|
||||
|
||||
# Get detailed pod information (replace with your actual pod name)
|
||||
kubectl describe pod jan-server-jan-inference-model-<POD_ID>
|
||||
```
|
||||
|
||||
**Common Error Messages and Solutions**:
|
||||
|
||||
##### Error: "Insufficient nvidia.com/gpu"
|
||||
```
|
||||
0/1 nodes are available: 1 Insufficient nvidia.com/gpu. no new claims to deallocate, preemption: 0/1 nodes are available: 1 Preemption is not helpful for scheduling.
|
||||
```
|
||||
**Solution for Real LLM Setup**:
|
||||
1. Ensure you have NVIDIA GPU and drivers installed
|
||||
2. Install NVIDIA Container Toolkit (see Prerequisites section)
|
||||
3. Start minikube with GPU support:
|
||||
```bash
|
||||
minikube start --gpus all
|
||||
```
|
||||
|
||||
##### Error: vLLM Pod Keeps Restarting
|
||||
```
|
||||
# Check pod logs to see the actual error
|
||||
kubectl logs jan-server-jan-inference-model-<POD_ID>
|
||||
```
|
||||
|
||||
**Common vLLM startup issues**:
|
||||
1. **CUDA Out of Memory**: Modify vLLM arguments in Dockerfile to reduce memory usage
|
||||
2. **Model Loading Errors**: Check if model path is correct and accessible
|
||||
3. **GPU Not Detected**: Ensure NVIDIA Container Toolkit is properly installed
|
||||
|
||||
### 2. Helm Issues
|
||||
|
||||
**Symptoms**: Helm commands fail or charts won't install.
|
||||
|
||||
**Solutions**:
|
||||
```bash
|
||||
# Update Helm dependencies
|
||||
helm dependency update ./charts/umbrella-chart
|
||||
|
||||
# Check Helm status
|
||||
helm list
|
||||
|
||||
# Uninstall and reinstall
|
||||
helm uninstall jan-server
|
||||
helm install jan-server ./charts/umbrella-chart
|
||||
```
|
||||
|
||||
### 3. Common Development Issues
|
||||
|
||||
**Pods in `ImagePullBackOff` state**
|
||||
- Ensure Docker images were built in the minikube environment
|
||||
- Run `eval $(minikube docker-env)` before building images
|
||||
|
||||
**Port forwarding connection refused**
|
||||
- Verify the service is running: `kubectl get svc`
|
||||
- Check pod status: `kubectl get pods`
|
||||
- Review logs: `kubectl logs deployment/jan-server-jan-api-gateway`
|
||||
|
||||
**Inference model download fails**
|
||||
- Ensure internet connectivity during Docker build
|
||||
- The Jan-v1-4B model is approximately 2.4GB
|
||||
|
||||
### Resource Requirements
|
||||
|
||||
**Minimum System Requirements:**
|
||||
- 8GB RAM
|
||||
- 20GB free disk space
|
||||
- 4 CPU cores
|
||||
|
||||
**Recommended System Requirements:**
|
||||
- 16GB RAM
|
||||
- 50GB free disk space
|
||||
- 8 CPU cores
|
||||
- GPU support (for faster inference)
|
||||
|
||||
The inference model requires significant memory. Ensure your minikube cluster has adequate resources allocated.
|
||||
@ -1,109 +0,0 @@
|
||||
---
|
||||
title: Overview
|
||||
description: A comprehensive self-hosted AI server platform that provides OpenAI-compatible APIs, multi-tenant organization management, and AI model inference capabilities.
|
||||
keywords:
|
||||
[
|
||||
Jan Server,
|
||||
self-hosted AI,
|
||||
Kubernetes deployment,
|
||||
Docker containers,
|
||||
AI inference,
|
||||
OpenAI compatible API,
|
||||
multi-tenant architecture,
|
||||
organization management,
|
||||
JWT authentication,
|
||||
Google OAuth2,
|
||||
API key management,
|
||||
Model Context Protocol,
|
||||
MCP,
|
||||
web search integration,
|
||||
PostgreSQL,
|
||||
monitoring,
|
||||
profiling
|
||||
]
|
||||
---
|
||||
|
||||
## Overview
|
||||
|
||||
Jan Server is a comprehensive self-hosted AI server platform that provides OpenAI-compatible APIs, multi-tenant organization management, and AI model inference capabilities. Jan Server enables organizations to deploy their own private AI infrastructure with full control over data, models, and access.
|
||||
|
||||
Jan Server is a Kubernetes-native platform consisting of multiple microservices that work together to provide a complete AI infrastructure solution. It offers:
|
||||
|
||||
- **OpenAI-Compatible API**: Full compatibility with OpenAI's chat completion API
|
||||
- **Multi-Tenant Architecture**: Organization and project-based access control
|
||||
- **AI Model Inference**: Scalable model serving with health monitoring
|
||||
- **Database Management**: PostgreSQL with read/write replicas
|
||||
- **Authentication & Authorization**: JWT + Google OAuth2 integration
|
||||
- **API Key Management**: Secure API key generation and management
|
||||
- **Model Context Protocol (MCP)**: Support for external tools and resources
|
||||
- **Web Search Integration**: Serper API integration for web search capabilities
|
||||
- **Monitoring & Profiling**: Built-in performance monitoring and health checks
|
||||
|
||||
## System Architecture
|
||||

|
||||
## Services
|
||||
|
||||
### Jan API Gateway
|
||||
The core API service that provides OpenAI-compatible endpoints and manages all client interactions.
|
||||
|
||||
**Key Features:**
|
||||
- OpenAI-compatible chat completion API with streaming support
|
||||
- Multi-tenant organization and project management
|
||||
- JWT-based authentication with Google OAuth2 integration
|
||||
- API key management at organization and project levels
|
||||
- Model Context Protocol (MCP) support for external tools
|
||||
- Web search integration via Serper API
|
||||
- Comprehensive monitoring and profiling capabilities
|
||||
- Database transaction management with automatic rollback
|
||||
|
||||
**Technology Stack:**
|
||||
- Go 1.24.6 with Gin web framework
|
||||
- PostgreSQL with GORM and read/write replicas
|
||||
- JWT authentication and Google OAuth2
|
||||
- Swagger/OpenAPI documentation
|
||||
- Built-in pprof profiling with Grafana Pyroscope integration
|
||||
|
||||
### Jan Inference Model
|
||||
The AI model serving service that handles model inference requests.
|
||||
|
||||
**Key Features:**
|
||||
- Scalable model serving infrastructure
|
||||
- Health monitoring and automatic failover
|
||||
- Load balancing across multiple model instances
|
||||
- Integration with various AI model backends
|
||||
|
||||
**Technology Stack:**
|
||||
- Python-based model serving
|
||||
- Docker containerization
|
||||
- Kubernetes-native deployment
|
||||
|
||||
### PostgreSQL Database
|
||||
The persistent data storage layer with enterprise-grade features.
|
||||
|
||||
**Key Features:**
|
||||
- Read/write replica support for high availability
|
||||
- Automatic schema migrations with Atlas
|
||||
- Connection pooling and optimization
|
||||
- Transaction management with rollback support
|
||||
|
||||
## Key Features
|
||||
|
||||
### Core Features
|
||||
- **OpenAI-Compatible API**: Full compatibility with OpenAI's chat completion API with streaming support and reasoning content handling
|
||||
- **Multi-Tenant Architecture**: Organization and project-based access control with hierarchical permissions and member management
|
||||
- **Conversation Management**: Persistent conversation storage and retrieval with item-level management, including message, function call, and reasoning content types
|
||||
- **Authentication & Authorization**: JWT-based auth with Google OAuth2 integration and role-based access control
|
||||
- **API Key Management**: Secure API key generation and management at organization and project levels with multiple key types (admin, project, organization, service, ephemeral)
|
||||
- **Model Registry**: Dynamic model endpoint management with automatic health checking and service discovery
|
||||
- **Streaming Support**: Real-time streaming responses with Server-Sent Events (SSE) and chunked transfer encoding
|
||||
- **MCP Integration**: Model Context Protocol support for external tools and resources with JSON-RPC 2.0
|
||||
- **Web Search**: Serper API integration for web search capabilities via MCP with webpage fetching
|
||||
- **Database Management**: PostgreSQL with read/write replicas and automatic migrations using Atlas
|
||||
- **Transaction Management**: Automatic database transaction handling with rollback support
|
||||
- **Health Monitoring**: Automated health checks with cron-based model endpoint monitoring
|
||||
- **Performance Profiling**: Built-in pprof endpoints for performance monitoring and Grafana Pyroscope integration
|
||||
- **Request Logging**: Comprehensive request/response logging with unique request IDs and structured logging
|
||||
- **CORS Support**: Cross-origin resource sharing middleware with configurable allowed hosts
|
||||
- **Swagger Documentation**: Auto-generated API documentation with interactive UI
|
||||
- **Email Integration**: SMTP support for invitation and notification systems
|
||||
- **Response Management**: Comprehensive response tracking with status management and usage statistics
|
||||
@ -54,52 +54,6 @@ const config: DocsThemeConfig = {
|
||||
navbar: {
|
||||
component: <Navbar />,
|
||||
},
|
||||
sidebar: {
|
||||
titleComponent: ({ type, title }) => {
|
||||
// eslint-disable-next-line react-hooks/rules-of-hooks
|
||||
const { asPath } = useRouter()
|
||||
if (type === 'separator' && title === 'Switcher') {
|
||||
return (
|
||||
<div className="-mx-2 hidden md:block">
|
||||
{(() => {
|
||||
const items = [
|
||||
{
|
||||
title: 'Jan Desktop',
|
||||
path: '/docs/desktop',
|
||||
Icon: LibraryBig,
|
||||
},
|
||||
{ title: 'Jan Server', path: '/docs/server', Icon: Computer },
|
||||
]
|
||||
return items.map((item) => {
|
||||
const active = asPath.startsWith(item.path)
|
||||
return active ? (
|
||||
<div
|
||||
key={item.path}
|
||||
className="group mb-3 flex flex-row items-center gap-3 nx-text-primary-800 dark:nx-text-primary-600"
|
||||
>
|
||||
<item.Icon className="w-7 h-7 p-1 border border-gray-200 dark:border-gray-700 rounded nx-bg-primary-100 dark:nx-bg-primary-400/10" />
|
||||
{item.title}
|
||||
</div>
|
||||
) : (
|
||||
<Link
|
||||
href={item.path}
|
||||
key={item.path}
|
||||
className="group mb-3 flex flex-row items-center gap-3 text-gray-500 hover:text-primary/100"
|
||||
>
|
||||
<item.Icon className="w-7 h-7 p-1 border rounded border-gray-200 dark:border-gray-700" />
|
||||
{item.title}
|
||||
</Link>
|
||||
)
|
||||
})
|
||||
})()}
|
||||
</div>
|
||||
)
|
||||
}
|
||||
return title
|
||||
},
|
||||
defaultMenuCollapseLevel: 1,
|
||||
toggleButton: true,
|
||||
},
|
||||
darkMode: false,
|
||||
toc: {
|
||||
backToTop: true,
|
||||
@ -107,22 +61,13 @@ const config: DocsThemeConfig = {
|
||||
head: function useHead() {
|
||||
const { title, frontMatter } = useConfig()
|
||||
const { asPath } = useRouter()
|
||||
const titleTemplate = asPath.includes('/post/')
|
||||
? (frontMatter?.title || title)
|
||||
: (asPath.includes('/desktop')
|
||||
? 'Jan Desktop'
|
||||
: asPath.includes('/server')
|
||||
? 'Jan Server'
|
||||
: 'Jan') +
|
||||
' - ' +
|
||||
(frontMatter?.title || title)
|
||||
|
||||
return (
|
||||
<Fragment>
|
||||
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
|
||||
<meta httpEquiv="Content-Language" content="en" />
|
||||
<title>{titleTemplate}</title>
|
||||
<meta name="og:title" content={titleTemplate} />
|
||||
<title>Jan</title>
|
||||
<meta name="og:title" content="Jan" />
|
||||
<meta
|
||||
name="description"
|
||||
content={
|
||||
|
||||
Loading…
x
Reference in New Issue
Block a user