---
title: Cortex.llamacpp
description: Cortex.llamacpp Architecture
keywords:
[
Jan,
Customizable Intelligence, LLM,
local AI,
privacy focus,
free and open source,
private and offline,
conversational AI,
no-subscription fee,
large language models,
Cortex,
Jan,
LLMs
]
---
import { Callout, Steps } from 'nextra/components'
import { Cards, Card } from 'nextra/components'
🚧 Cortex is under construction.
# Cortex.llamacpp
Cortex.llamacpp is a C++ inference library that can be loaded by any server at runtime. It submodules (and occasionally upstreams) [llama.cpp](https://github.com/ggerganov/llama.cpp) for GGUF inference.
In addition to llama.cpp, cortex.llamacpp adds:
- OpenAI compatibility for the stateless endpoints
- Model orchestration like model warm up and concurrent models
Cortex.llamacpp is formerly called "Nitro".
If you already use [Jan](/docs) or [Cortex](/cortex), cortex.llamacpp is bundled by default and you don’t need this guide. This guides walks you through how to use cortex.llamacpp as a standalone library, in any custom C++ server.
## Usage
To include cortex.llamacpp in your own server implementation, follow this [server example](https://github.com/menloresearch/cortex.llamacpp/tree/main/examples/server).
## Interface
Cortex.llamacpp has the following Interfaces:
- **HandleChatCompletion:** Processes chat completion tasks
```cpp
void HandleChatCompletion(
std::shared_ptr jsonBody,
std::function&& callback);
```
- **HandleEmbedding:** Generates embeddings for the input data provided
```cpp
void HandleEmbedding(
std::shared_ptr jsonBody,
std::function&& callback);
```
- **LoadModel:** Loads a model based on the specifications
```cpp
void LoadModel(
std::shared_ptr jsonBody,
std::function&& callback);
```
- **UnloadModel:** Unloads a model as specified
```cpp
void UnloadModel(
std::shared_ptr jsonBody,
std::function&& callback);
```
- **GetModelStatus:** Retrieves the status of a model
```cpp
void GetModelStatus(
std::shared_ptr jsonBody,
std::function&& callback);
```
**Parameters:**
- **`jsonBody`**: The request content in JSON format.
- **`callback`**: A function that handles the response
## Architecture
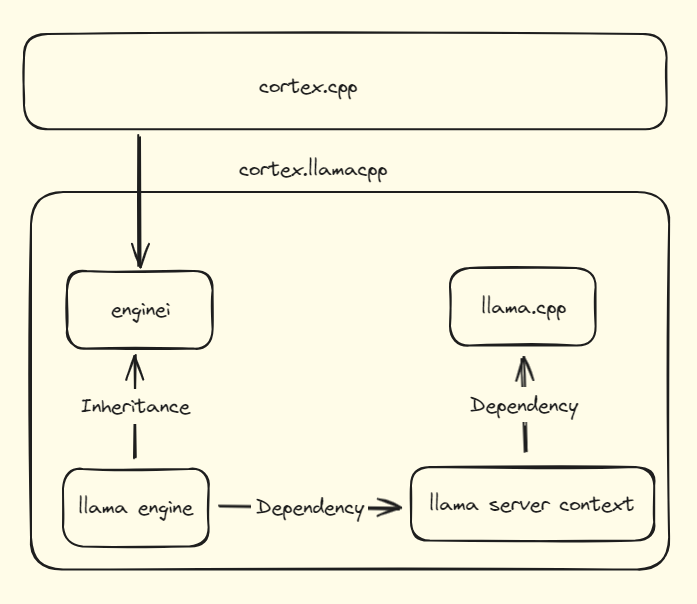
The main components include:
- `enginei`: an engine interface definition that extends to all engines, handling endpoint logic and facilitating communication between `cortex.cpp` and `llama engine`.
- `llama engine`: exposes APIs for embedding and inference. It loads and unloads models and simplifies API calls to `llama.cpp`.
- `llama.cpp`: submodule from the `llama.cpp` repository that provides the core functionality for embeddings and inferences.
- `llama server context`: a wrapper offers a simpler and more user-friendly interface for `llama.cpp` APIs
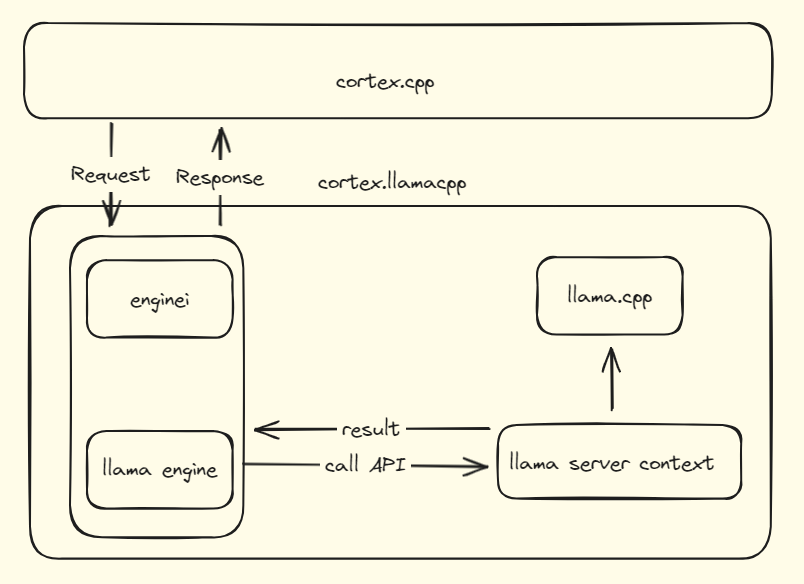
### Communication Protocols:
- `Streaming`: Responses are processed and returned one token at a time.
- `RESTful`: The response is processed as a whole. After the llama server context completes the entire process, it returns a single result back to cortex.cpp.
## Code Structure
```
.
├── base # Engine interface definition
| └── cortex-common # Common interfaces used for all engines
| └── enginei.h # Define abstract classes and interface methods for engines
├── examples # Server example to integrate engine
│ └── server.cc # Example server demonstrating engine integration
├── llama.cpp # Upstream llama.cpp repository
│ └── (files from upstream llama.cpp)
├── src # Source implementation for llama.cpp
│ ├── chat_completion_request.h # OpenAI compatible request handling
│ ├── llama_client_slot # Manage vector of slots for parallel processing
│ ├── llama_engine # Implementation of llamacpp engine for model loading and inference
│ ├── llama_server_context # Context management for chat completion requests
│ │ ├── slot # Struct for slot management
│ │ └── llama_context # Struct for llama context management
| | └── chat_completion # Struct for chat completion management
| | └── embedding # Struct for embedding management
├── third-party # Dependencies of the cortex.llamacpp project
│ └── (list of third-party dependencies)
```
## Runtime
## Roadmap
The future plans for Cortex.llamacpp are focused on enhancing performance and expanding capabilities. Key areas of improvement include:
- Performance Enhancements: Optimizing speed and reducing memory usage to ensure efficient processing of tasks.
- Multimodal Model Compatibility: Expanding support to include a variety of multimodal models, enabling a broader range of applications and use cases.
To follow the latest developments, see the [cortex.llamacpp GitHub](https://github.com/menloresearch/cortex.llamacpp)