* chore: enable shortcut zoom (#5261) * chore: enable shortcut zoom * chore: update shortcut setting * fix: thinking block (#5263) * Merge pull request #5262 from menloresearch/chore/sync-new-hub-data chore: sync new hub data * ✨enhancement: model run improvement (#5268) * fix: mcp tool error handling * fix: error message * fix: trigger download from recommend model * fix: can't scroll hub * fix: show progress * ✨enhancement: prompt users to increase context size * ✨enhancement: rearrange action buttons for a better UX * 🔧chore: clean up logics --------- Co-authored-by: Faisal Amir <urmauur@gmail.com> * fix: glitch download from onboarding (#5269) * ✨enhancement: Model sources should not be hard coded from frontend (#5270) * 🐛fix: default onboarding model should use recommended quantizations (#5273) * 🐛fix: default onboarding model should use recommended quantizations * ✨enhancement: show context shift option in provider settings * 🔧chore: wording * 🔧 config: add to gitignore * 🐛fix: Jan-nano repo name changed (#5274) * 🚧 wip: disable showSpeedToken in ChatInput * 🐛 fix: commented out the wrong import * fix: masking value MCP env field (#5276) * ✨ feat: add token speed to each message that persist * ♻️ refactor: to follow prettier convention * 🐛 fix: exclude deleted field * 🧹 clean: all the missed console.log * ✨enhancement: out of context troubleshooting (#5275) * ✨enhancement: out of context troubleshooting * 🔧refactor: clean up * ✨enhancement: add setting chat width container (#5289) * ✨enhancement: add setting conversation width * ✨enahncement: cleanup log and change improve accesibility * ✨enahcement: move const beta version * 🐛fix: optional additional_information gpu (#5291) * 🐛fix: showing release notes for beta and prod (#5292) * 🐛fix: showing release notes for beta and prod * ♻️refactor: make an utils env * ♻️refactor: hide MCP for production * ♻️refactor: simplify the boolean expression fetch release note * 🐛fix: typo in build type check (#5297) * 🐛fix: remove onboarding local model and hide the edit capabilities model (#5301) * 🐛fix: remove onboarding local model and hide the edit capabilities model * ♻️refactor: conditional search params setup screen * 🐛fix: hide token speed when assistant params stream false (#5302) * 🐛fix: glitch padding speed token (#5307) * 🐛fix: immediately show download progress (#5308) * 🐛fix:safely convert values to numbers and handle NaN cases (#5309) * chore: correct binary name for stable version (#5303) (#5311) Co-authored-by: hiento09 <136591877+hiento09@users.noreply.github.com> * 🐛fix: llama.cpp default NGL setting does not offload all layers to GPU (#5310) * 🐛fix: llama.cpp default NGL setting does not offload all layers to GPU * chore: cover more cases * chore: clean up * fix: should not show GPU section on Mac * 🐛fix: update default extension settings (#5315) * fix: update default extension settings * chore: hide language setting on Prod * 🐛fix: allow script posthog (#5316) * Sync 0.5.18 to 0.6.0 (#5320) * chore: correct binary name for stable version (#5303) * ci: enable devtool on prod build (#5317) * ci: enable devtool on prod build --------- Co-authored-by: hiento09 <136591877+hiento09@users.noreply.github.com> Co-authored-by: Nguyen Ngoc Minh <91668012+Minh141120@users.noreply.github.com> * fix: glitch model download issue (#5322) * 🐛 fix(updater): terminate sidecar processes before update to avoid file access errors (#5325) * 🐛 fix: disable sorting for threads in SortableItem and clean up thread order handling (#5326) * improved wording in UI elements (#5323) * fix: sorted-thread-not-stable (#5336) * 🐛fix: update wording desc vulkan (#5338) * 🐛fix: update wording desc vulkan * ✨enhancement: update copy * 🐛fix: handle NaN value tokenspeed (#5339) * 🐛 fix: window path problem * feat(server): filter /models endpoint to show only downloaded models (#5343) - Add filtering logic to proxy server for GET /models requests - Keep only models with status "downloaded" in response - Remove Content-Length header to prevent mismatch after filtering - Support both ListModelsResponseDto and direct array formats - Add comprehensive tests for filtering functionality - Fix Content-Length header conflict causing empty responses Fixes issue where all models were returned regardless of download status. * 🐛fix: render streaming token speed based on thread ID & assistant metadata (#5346) * fix(server): add gzip decompression support for /models endpoint filtering (#5349) - Add gzip detection using magic number check (0x1f 0x8b) - Implement gzip decompression before JSON parsing - Add gzip re-compression for filtered responses - Fix "invalid utf-8 sequence" error when upstream returns gzipped content - Maintain Content-Encoding consistency for compressed responses - Add comprehensive gzip handling with flate2 library Resolves issue where filtering failed on gzip-compressed model responses. * fix(proxy): implement true HTTP streaming for chat completions API (#5350) * fix: glitch toggle gpus (#5353) * fix: glitch toogle gpu * fix: Using the GPU's array index as a key for gpuLoading * enhancement: added try-finally * fix: built in models capabilities (#5354) * 🐛fix: setting provider hide model capabilities (#5355) * 🐛fix: setting provider hide model capabilities * 🐛fix: hide tools icon on dropdown model providers * fix: stop server on app close or reload * ✨enhancement: reset heading class --------- Co-authored-by: Louis <louis@jan.ai> * fix: stop api server on page unload (#5356) * fix: stop api server on page unload * fix: check api server status on reload * refactor: api server state * fix: should not pop the guard * 🐛fix: avoid render html title thread (#5375) * 🐛fix: avoid render html title thread * chore: minor bump - tokenjs for manual adding models --------- Co-authored-by: Louis <louis@jan.ai> --------- Co-authored-by: Faisal Amir <urmauur@gmail.com> Co-authored-by: LazyYuuki <huy2840@gmail.com> Co-authored-by: Bui Quang Huy <34532913+LazyYuuki@users.noreply.github.com> Co-authored-by: hiento09 <136591877+hiento09@users.noreply.github.com> Co-authored-by: Nguyen Ngoc Minh <91668012+Minh141120@users.noreply.github.com> Co-authored-by: Sam Hoang Van <samhv.ict@gmail.com> Co-authored-by: Ramon Perez <ramonpzg@protonmail.com>
{kind=link}
{kind=link}
Jan - Local AI Assistant





Getting Started - Docs - Changelog - Bug reports - Discord
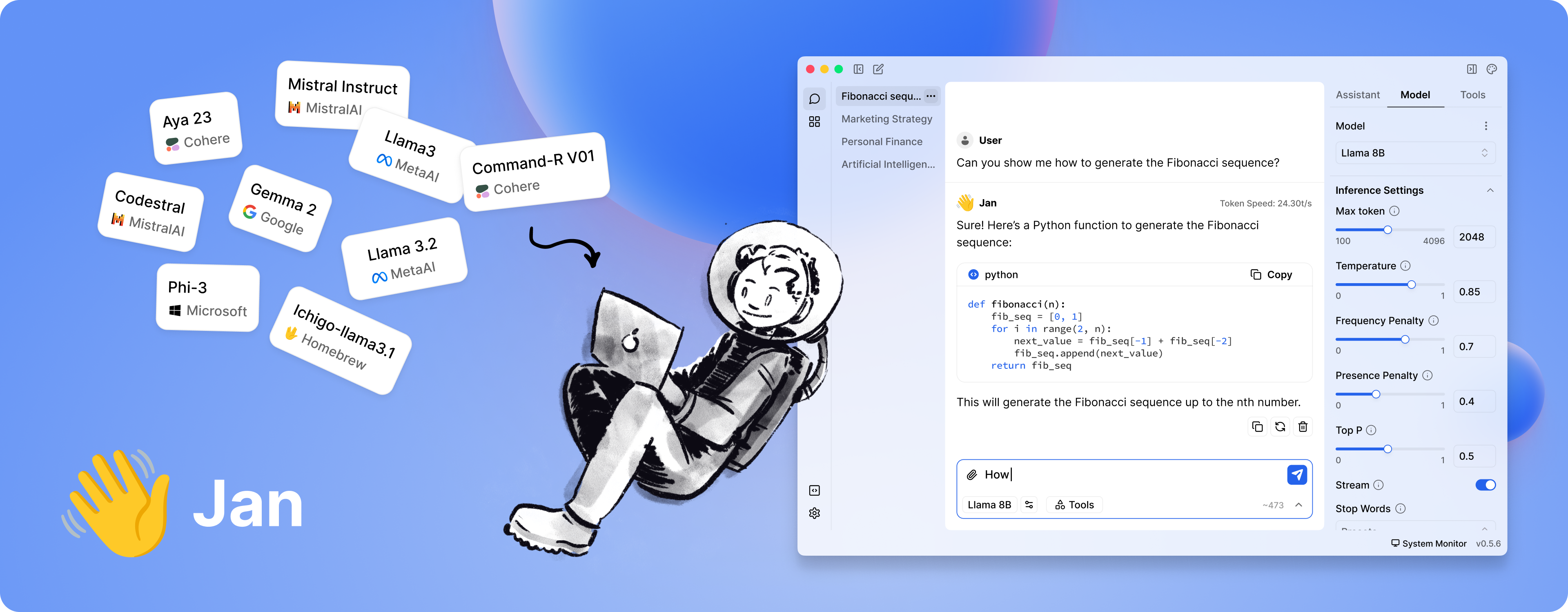
Jan is a ChatGPT-alternative that runs 100% offline on your device. Our goal is to make it easy for a layperson to download and run LLMs and use AI with full control and privacy.
⚠️ Jan is in active development.
Installation
Because clicking a button is still the easiest way to get started:
| Platform | Stable | Beta | Nightly |
| Windows | jan.exe | jan.exe | jan.exe |
| macOS | jan.dmg | jan.dmg | jan.dmg |
| Linux (deb) | jan.deb | jan.deb | jan.deb |
| Linux (AppImage) | jan.AppImage | jan.AppImage | jan.AppImage |
Download from jan.ai or GitHub Releases.
Demo
Features
- Local AI Models: Download and run LLMs (Llama, Gemma, Qwen, etc.) from HuggingFace
- Cloud Integration: Connect to OpenAI, Anthropic, Mistral, Groq, and others
- Custom Assistants: Create specialized AI assistants for your tasks
- OpenAI-Compatible API: Local server at
localhost:1337for other applications - Model Context Protocol: MCP integration for enhanced capabilities
- Privacy First: Everything runs locally when you want it to
Build from Source
For those who enjoy the scenic route:
Prerequisites
- Node.js ≥ 20.0.0
- Yarn ≥ 1.22.0
- Make ≥ 3.81
- Rust (for Tauri)
Quick Start
git clone https://github.com/menloresearch/jan
cd jan
make dev
This handles everything: installs dependencies, builds core components, and launches the app.
Alternative Commands
If you prefer the verbose approach:
# Setup and development
yarn install
yarn build:core
yarn build:extensions
yarn dev
# Production build
yarn build
# Clean slate (when things inevitably break)
make clean
Available Make Targets
make dev- Full development setup and launch (recommended)make dev-tauri- Tauri development (deprecated, usemake dev)make build- Production buildmake install-and-build- Install dependencies and build core/extensionsmake test- Run tests and lintingmake lint- Check your code doesn't offend the lintersmake clean- Nuclear option: delete everything and start fresh
System Requirements
Minimum specs for a decent experience:
- macOS: 13.6+ (8GB RAM for 3B models, 16GB for 7B, 32GB for 13B)
- Windows: 10+ with GPU support for NVIDIA/AMD/Intel Arc
- Linux: Most distributions work, GPU acceleration available
For detailed compatibility, check our installation guides.
Troubleshooting
When things go sideways (they will):
- Check our troubleshooting docs
- Copy your error logs and system specs
- Ask for help in our Discord
#🆘|jan-helpchannel
We keep logs for 24 hours, so don't procrastinate on reporting issues.
Contributing
Contributions welcome. See CONTRIBUTING.md for the full spiel.
Links
- Documentation - The manual you should read
- API Reference - For the technically inclined
- Changelog - What we broke and fixed
- Discord - Where the community lives
Contact
- Bugs: GitHub Issues
- Business: hello@jan.ai
- Jobs: hr@jan.ai
- General Discussion: Discord
Trust & Safety
Friendly reminder: We're not trying to scam you.
- We won't ask for personal information
- Jan is completely free (no premium version exists)
- We don't have a cryptocurrency or ICO
- We're bootstrapped and not seeking your investment (yet)
License
Apache 2.0 - Because sharing is caring.
Acknowledgements
Built on the shoulders of giants: