8.6 KiB
| title | description | slug | tags | authors | |||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| RAG is not enough: Lessons from Beating GPT-3.5 on Specialized Tasks with Mistral 7B | Creating Open Source Alternatives to Outperform ChatGPT | /surpassing-chatgpt-with-open-source-alternatives |
|
|
Abstract
We present a straightforward approach to adapting small, open-source models for specialized use-cases, that can surpass GPT 3.5 performance with RAG. With it, we were able to get superior results on Q&A over technical documentation describing a small codebase.
In short, (1) extending a general foundation model like Mistral with strong math and coding, and (2) training it over a high-quality, synthetic dataset generated from the intended corpus, and (3) adding RAG capabilities, can lead to significant accuracy improvements.
Problems still arise with catastrophic forgetting in general tasks, commonly observed during continued fine-tuning [1]. In our case, this is likely exacerbated by our lack of access to Mistral’s original training dataset and various compression techniques used in our approach to keep the model small.
Selecting a strong foundation model
Mistral 7B continues to outshine Meta's Llama-2 7B and Google's Gemma 7B on meaningful benchmarks, so we selected this as a starting point.
Having a robust base model is critical. In our experiments, using Mistral as a starting point ensured the highest accuracy for subsequent specialized adaptations.
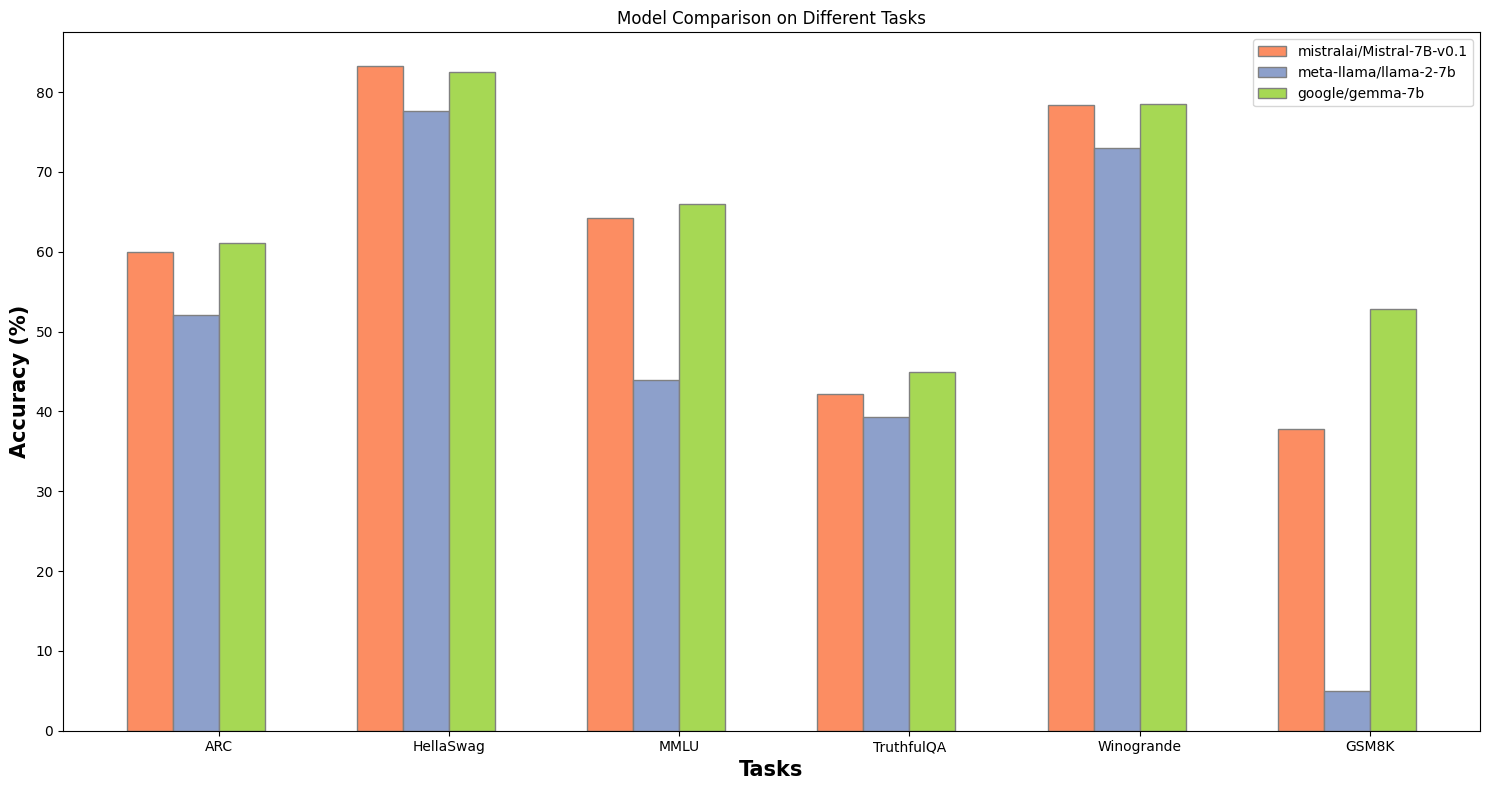
Figure 1. Mistral 7B excels in benchmarks, ranking among the top foundational models.
Note: we are not sponsored by the Mistral team. Though many folks in their community do like to run Mistral locally using our desktop client - Jan.
Cost effectively improving the base model
Mistral alone has known, poor math capabilities, which we needed for our highly technical use case. Thus, we tested all model variants on top of Mistral, from foundation models to finetunes to model merges, in order to find a stronger base model to receive our own finetuning.
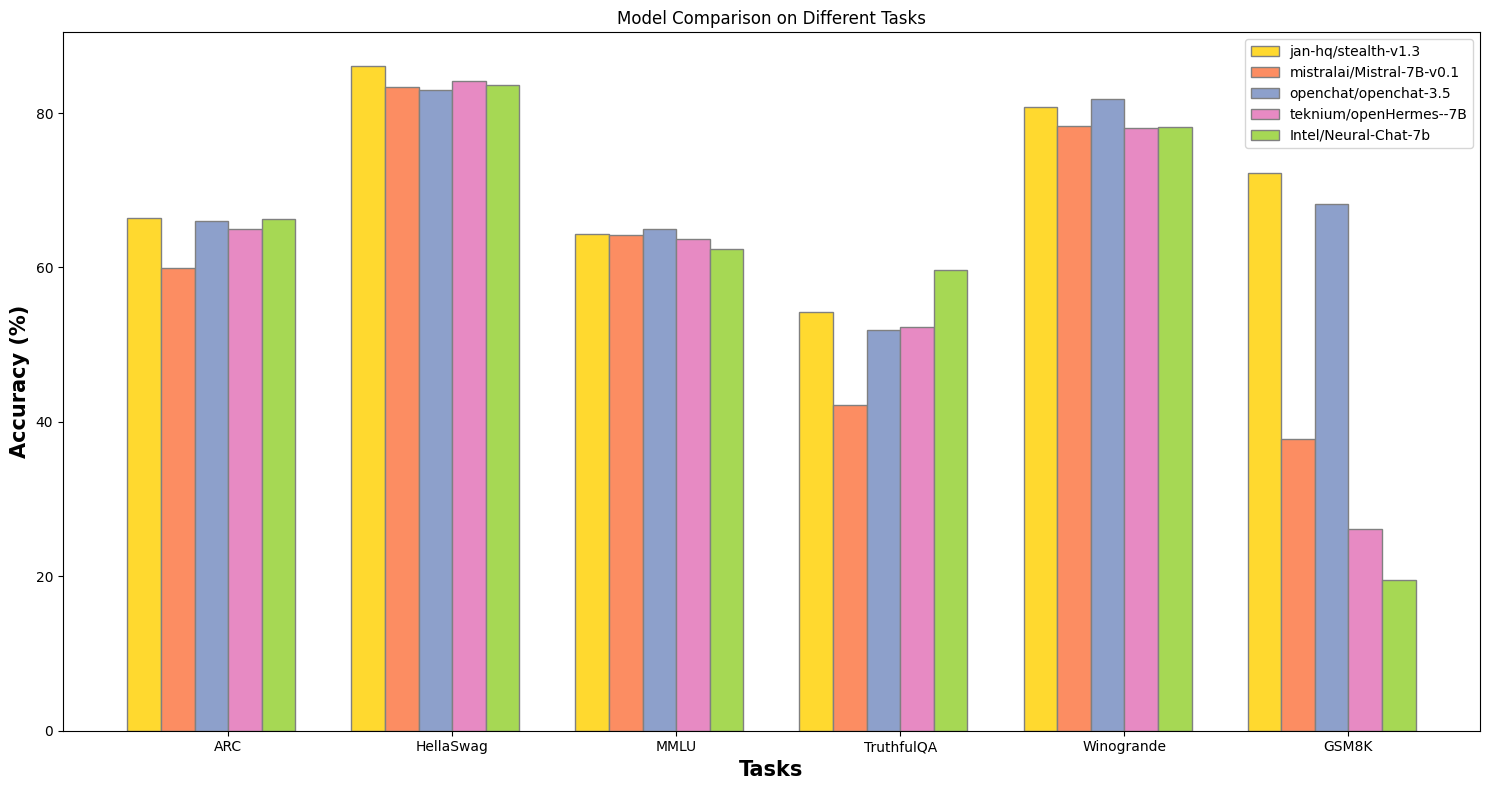
Figure 2: The merged model, Stealth, doubles the mathematical capabilities of its foundational model while retaining the performance in other tasks.
We found model merging to be a viable approach where each iteration is cost-effective + fast to deploy.
We ended up with Stealth 7B v1.1, a SLERP merge of Mistral with the following:
- WizardMath for its math capabilities
- WizardCoder for its coding capabilities
- Our own Trinity model for its versatility across general tasks
This particular combination yielded the best tradeoff across mathematical & technical reasoning while retaining the most pre-merge performance on general tasks.
DPO finetuning
Merging different LLMs can lead to the mixed answering style because each model was originally trained on different types of data.
Thus, we applied Direct Preference Optimization (DPO) using the Intel's Orca DPO pairs dataset, chosen for its helpful answering style in general, math and coding concentration.
This approach result in a final model - Stealth 7B v1.2, with minimal loss, and realign to our technical preferences.
Using our own technical documentation
With the base model ready, we started on our specific use case.
Jan is an open-source & bootstrapped project - at one point during our unanticipated growth, we received 1 customer support ticket per minute, with no one to handle customer service.
So, we directed our efforts toward training a model to answer user questions based on existing technical documentation.
Specifically, we trained it on Nitro docs. For context, Nitro is the default inference engine for Jan. It’s a serious server implementation of LlamaCPP, written in C++, with multimodal, queues, and other production-level server capabilities.
It made an interesting corpus because it was rife with post-2023 technical jargon, edge cases, and poor informational layout.
Generating a training dataset for GPT-4 and training
The first step was to transform Nitro’s unstructured format into a synthetic Q&A dataset designed for instruction tuning.
The text was split into chunks of 300-token segments with 30-token overlaps. This helped to avoid a lost-in-the-middle problem where LLM can’t use context efficiently to answer given questions.
The chunks were then given to GPT-4 with 8k context length to generate 3800 Q&A pairs. The training dataset is available on HuggingFace.
Training
Training was done with supervised finetuning (SFT) from the Hugging Face's alignment-handbook, per Huggingface's Zephyr Beta guidelines.
We used consumer-grade, dual Nvidia RTX 4090s for the training. The end-to-end training took 18 minutes. We found optimal hyperparameters in LoRA for this specific task to be r = 256 and alpha = 512.
This final model can be found here on Huggingface.
Figure 3. Using the new finetuned model in Jan
Improving results with RAG
As an additional step, we also added Retrieval Augmented Generation (RAG) as an experiment parameter.
A simple RAG setup was done using Llamaindex and the bge-en-base-v1.5 embedding model for efficient documentation retrieval and question-answering. You can find the RAG implementation here.
Benchmarking the Results
We curated a new set of 50 multiple-choice questions (MCQ) based on the Nitro docs. The questions had varying levels of difficulty and had trick components that challenged the model's ability to discern misleading information.
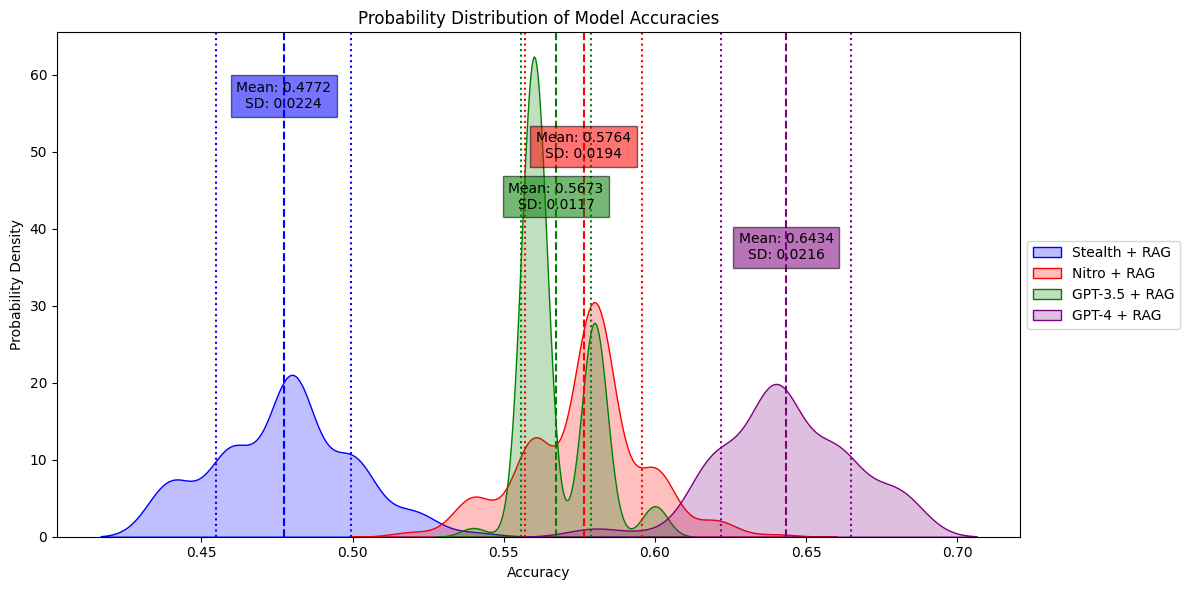
Figure 4. Comparation between finetuned model and OpenAI's GPT
Results
- GPT-3.5 with RAG: 56.7%
- GPT-4 with RAG: 64.3%
- Merged 7B Model (Stealth) with RAG: 47.7%
- Finetuned 7B Model (Nitro) with RAG: 57.8%
This indicates that with task-specific training, we can improve an open-source, Small Language Model to the level of GPT-3.5 on domain knowledge.
Notably, the finetuned + RAG approach also demonstrated more consistency across benchmarking, as indicated by its lower standard deviation.
Conclusion
We conclude that this combination of model merging + finetuning + RAG yields promise. This finding is relevant for teams and individuals that need specialized, technical SLMs that need to run in resource-constrained or highly secured environments, where GPT may not be an option.
Anecdotally, we’ve had some success using this model in practice to onboard new team members to the Nitro codebase.
A full research report with more statistics can be found here.