3.8 KiB
| title | description | slug | tags | authors | |||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| RAG is not enough: Lessons from Beating GPT-3.5 on Specialized Tasks with Mistral 7B | Creating Open Source Alternatives to Outperform ChatGPT | /surpassing-chatgpt-with-open-source-alternatives |
|
|
Abstract
We present a straightforward approach to adapting small, open-source models for specialized use-cases, that can surpass GPT 3.5 performance with RAG. With it, we were able to get superior results on Q&A over technical documentation describing a small codebase.
In short, (1) extending a general foundation model like Mistral with strong math and coding, and (2) training it over a high-quality, synthetic dataset generated from the intended corpus, and (3) adding RAG capabilities, can lead to significant accuracy improvements.
Problems still arise with catastrophic forgetting in general tasks, commonly observed during continued fine-tuning [1]. In our case, this is likely exacerbated by our lack of access to Mistral’s original training dataset and various compression techniques used in our approach to keep the model small.
Selecting a strong foundation model
Mistral 7B continues to outshine Meta's Llama-2 7B and Google's Gemma 7B on meaningful benchmarks, so we selected this as a starting point.
Having a robust base model is critical. In our experiments, using Mistral as a starting point ensured the highest accuracy for subsequent specialized adaptations.
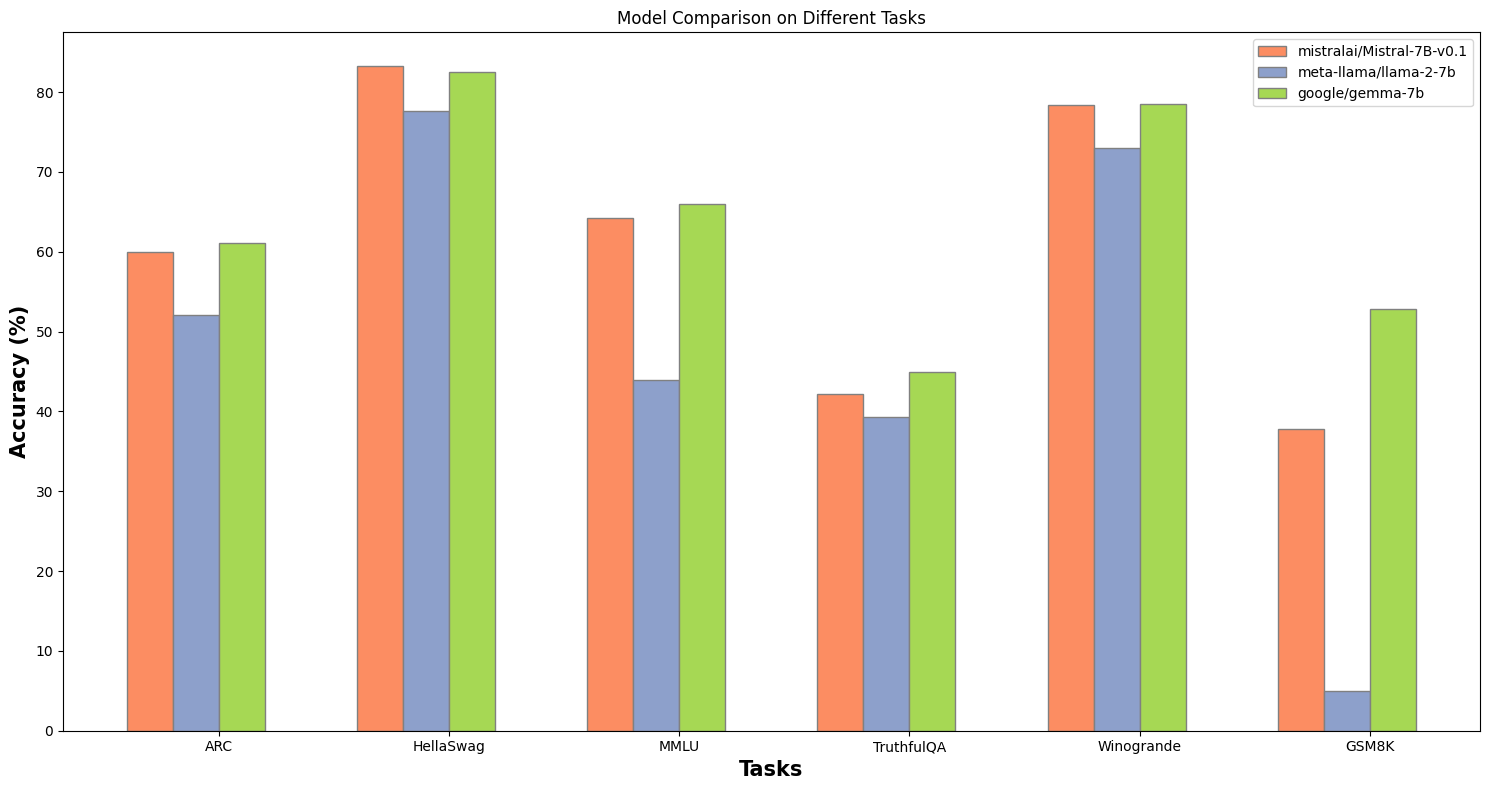
Figure 1. Mistral 7B excels in benchmarks, ranking among the top foundational models.
Note: we are not sponsored by the Mistral team. Though many folks in their community do like to run Mistral locally using our desktop client - Jan.
Cost effectively improving the base model
Mistral alone has known, poor math capabilities, which we needed for our highly technical use case. Thus, we tested all model variants on top of Mistral, from foundation models to finetunes to model merges, in order to find a stronger base model to receive our own finetuning.
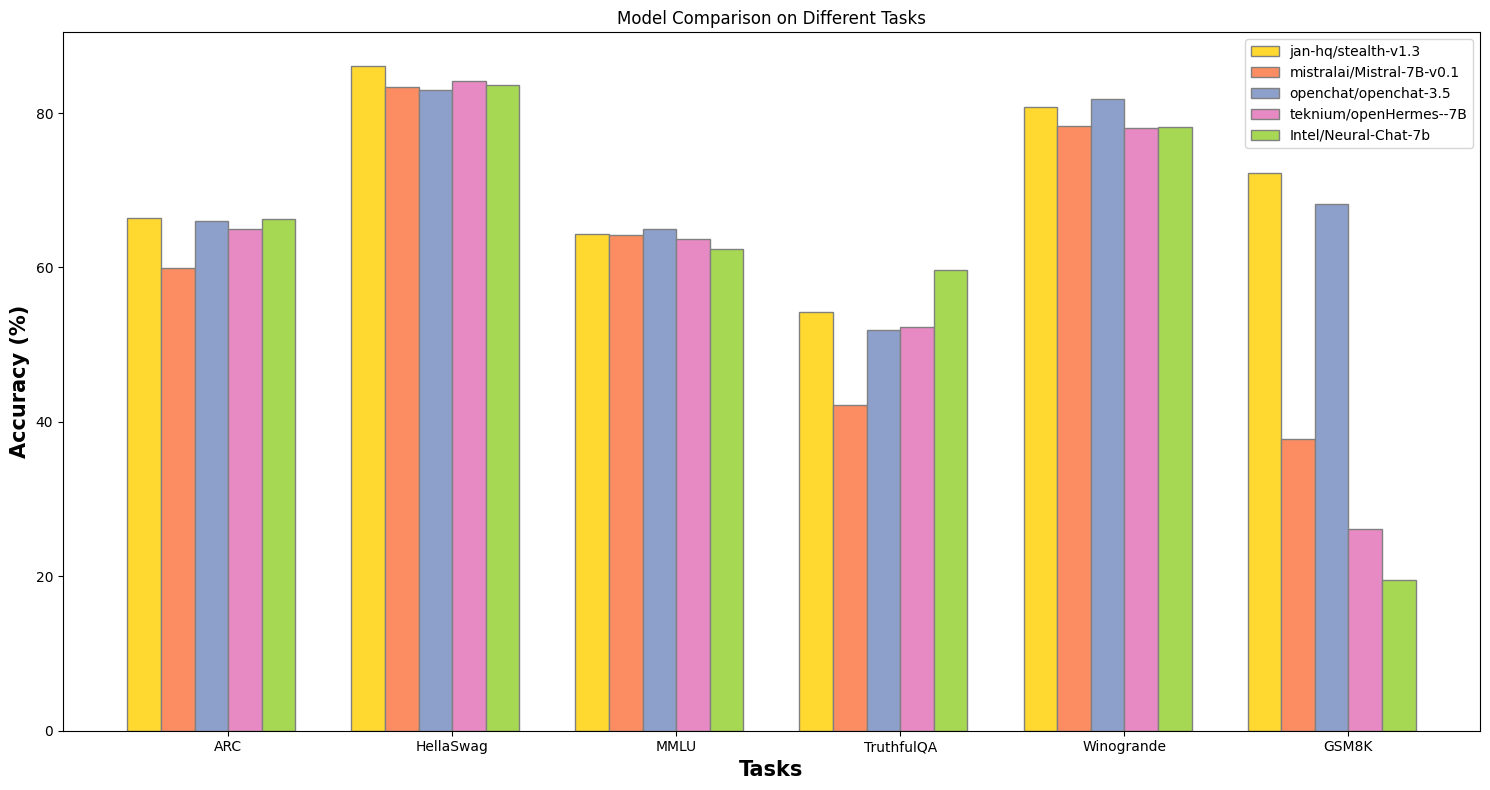
Figure 2: The merged model, Stealth, doubles the mathematical capabilities of its foundational model while retaining the performance in other tasks.
We found model merging to be a viable approach where each iteration is cost-effective + fast to deploy.
We ended up with Stealth, a SLERP merge of Mistral with the following:
- WizardMath for its math capabilities
- WizardCoder for its coding capabilities
- Our own Trinity model for its versatility across general tasks
This particular combination yielded the best tradeoff across mathematical & technical reasoning while retaining the most pre-merge performance on general tasks.